AI Config Management: An Operating Model for Runtime Control
AI config management is the discipline of managing production AI behavior as versioned, owned, measurable, and reversible runtime configuration. It covers prompts, model routes, retrieval profiles, guardrails, tool policies, fallback paths, rollout rules, and experiment variants.
The practical problem is not only where the values live. It is how the team prevents a prompt edit, model switch, retrieval expansion, threshold change, or agent tool mode from becoming an unreviewed release. Good AI config management turns runtime flexibility into a controlled release system: every meaningful config has an owner, schema, fallback, rollout path, evidence rule, rollback action, and cleanup decision.

What AI Config Management Includes
AI configuration is broader than a settings file or prompt table. In a production AI system, config can decide:
| Config surface | What changes at runtime | Management question |
|---|---|---|
| Prompt or instruction profile | System prompts, prompt templates, tone, task policy, citation rules | Who approved the behavior and which version is active? |
| Model route | Provider, model version, model tier, timeout, cost profile, fallback model | Which users or workflows should receive the candidate route first? |
| Retrieval profile | Index, source scope, filters, reranker, chunk count, memory scope | Does the profile respect data boundaries and answer-quality evidence? |
| Guardrail mode | Confidence threshold, review rule, block rule, escalation threshold | What evidence allows the threshold to expand? |
| Agent tool policy | Disabled, observe-only, read-only, draft, approval-required, write-capable | Which hard authorization boundary still applies outside the flag? |
| Fallback behavior | Baseline model, cached answer, human handoff, feature off | Can operators return to baseline without redeploying? |
| Rollout rule | Internal, beta, segment, percentage, region, plan, experiment | What audience receives the behavior and how is exposure measured? |
The same config value can be both a product decision and an operations decision. A model route may improve quality but raise latency. A retrieval profile may improve grounding but widen data access. A guardrail threshold may reduce false blocks while increasing risky output. A tool policy may improve task completion while creating side effects.
That is why AI config management should be treated as release management, not only configuration storage.
The Minimum AI Config Contract
Before a config reaches production, define a compact contract that reviewers, operators, and future maintainers can understand.
ai_config:
key: support_answer_profile
owner: support_ai_platform
controlled_surface:
- prompt_profile
- model_route
- retrieval_profile
- fallback_behavior
baseline: support_baseline_v3
candidate: support_citation_first_v4
assignment_unit: account
first_audience: internal_support_users
rollout_path:
- internal
- 5_percent_beta_accounts
- 25_percent_eligible_accounts
primary_metric: resolved_conversation_without_escalation
guardrails:
- citation_failure_rate
- latency_p95
- fallback_rate
- estimated_cost_per_case
rollback: return_targeted_accounts_to_support_baseline_v3
cleanup: promote_winner_or_remove_candidate_after_decision
The exact fields can differ by team, but the contract should answer six questions:
- What behavior changes?
- Who owns the change?
- Where is the safe fallback?
- Who sees the candidate first?
- What evidence decides expansion?
- What happens after the decision?
FeatBit's AI control layer framing is useful here: each AI decision point becomes a named runtime control surface. The config contract makes that surface reviewable.
Manage Config As Profiles, Not Loose Knobs
Loose knobs look flexible:
support_model = "candidate"
support_temperature = 0.4
support_retrieval_k = 8
support_guardrail_mode = "standard"
support_timeout_ms = 9000
The problem is that every knob can combine with every other knob. A team can accidentally create a production behavior nobody reviewed as a whole.
Prefer named profiles:
{
"profile": "support_citation_first_v4",
"promptProfile": "support_answer_citation_first_v4",
"modelRoute": "balanced_support",
"retrievalProfile": "verified_docs_rerank_v2",
"guardrailMode": "standard",
"timeoutMs": 9000,
"maxOutputTokens": 900,
"fallback": "human_escalation"
}
A profile is easier to approve, target, measure, roll back, and clean up. It also makes the difference between "change a value" and "release a behavior" visible to the team.
FeatBit supports this pattern with multivariate flag variations, including string, number, and JSON values, and with remote config for behavior that is more specific than a boolean on/off switch.
A Runtime Management Loop
AI config management should produce a repeatable loop, not a one-time settings workflow.
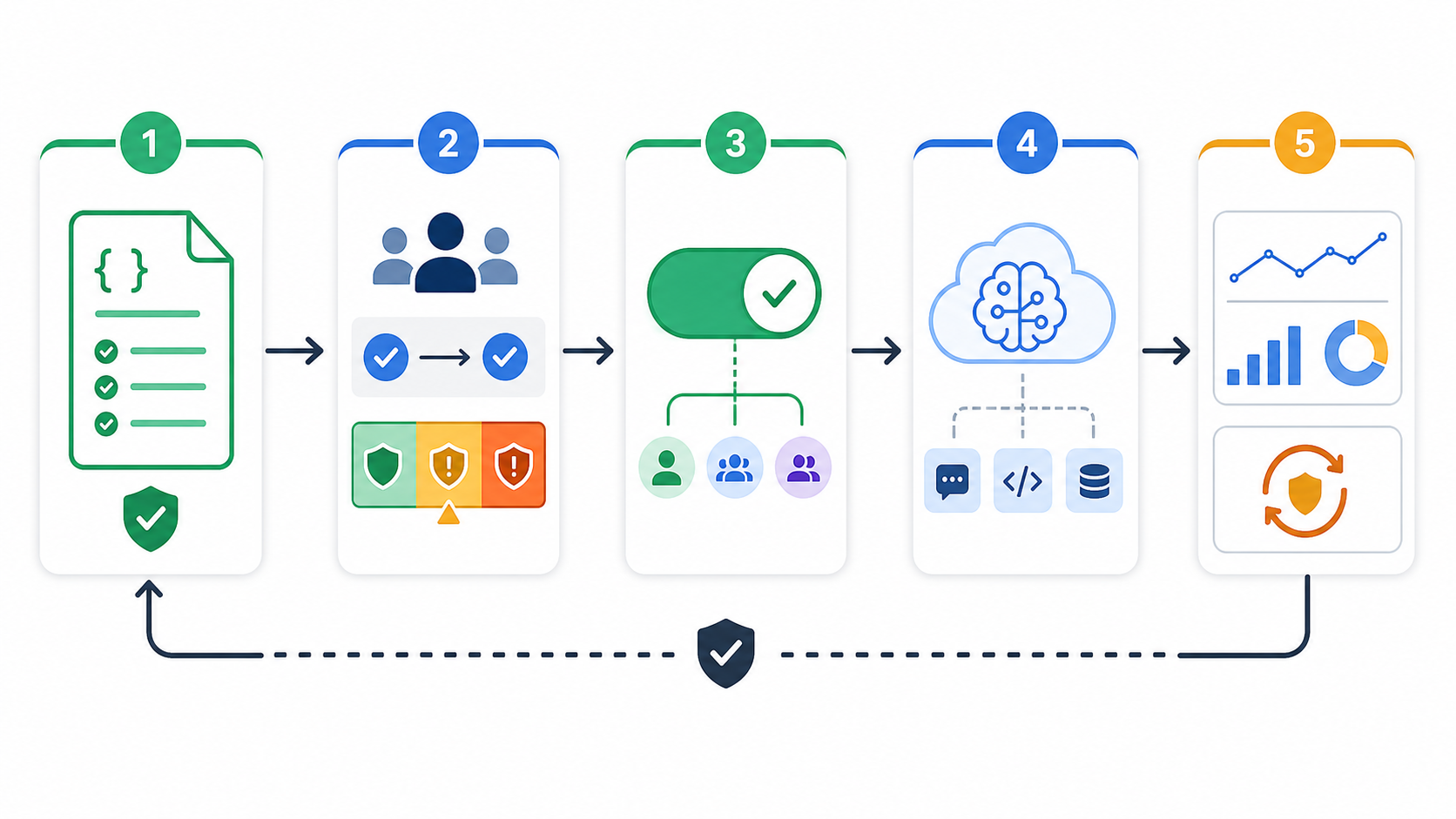
| Stage | What the team does | What FeatBit helps control |
|---|---|---|
| Define | Name the config profile, owner, schema, fallback, and release question. | Flag key, variations, environments, lifecycle expectation. |
| Review | Classify risk and attach the right evidence before exposure. | Audit history, IAM, change workflow, environment separation. |
| Target | Serve the candidate to internal users, beta accounts, a segment, or a percentage. | Targeting rules, user segments, percentage rollout. |
| Measure | Record which profile actually ran and connect it to quality, latency, cost, fallback, and outcome events. | Flag insights, variation events, Track Insights API, experiment metrics. |
| Decide | Promote, pause, roll back, segment, iterate, or clean up. | Rollback through variation changes, archive policy, lifecycle review. |
OpenFeature's flag evaluation specification is useful vendor-neutral language because it frames evaluation as a typed call with a flag key, default value, context, and evaluation result. For AI config, that shape matters: the application should evaluate a typed config before prompt assembly, model routing, retrieval, guardrail checks, or tool selection.
The request path should usually look like this:
type SupportAiConfig = {
profile: "baseline_v3" | "citation_first_v4" | "fallback";
promptProfile: string;
modelRoute: string;
retrievalProfile: string;
guardrailMode: "standard" | "strict" | "fallback_first";
fallback: "human_escalation" | "cached_answer";
};
const fallbackConfig: SupportAiConfig = {
profile: "baseline_v3",
promptProfile: "support_answer_v3",
modelRoute: "balanced_support",
retrievalProfile: "verified_docs_baseline",
guardrailMode: "standard",
fallback: "human_escalation",
};
async function answerSupportQuestion(request: SupportRequest) {
const context = {
keyId: request.accountId,
plan: request.plan,
region: request.region,
workflow: "support_answer",
riskTier: request.riskTier,
};
const config = await flags.jsonVariation<SupportAiConfig>(
"support_answer_profile",
context,
fallbackConfig
);
const profile = validateSupportAiConfig(config) ? config : fallbackConfig;
const response = await runSupportAiPipeline({
question: request.question,
promptProfile: profile.promptProfile,
modelRoute: profile.modelRoute,
retrievalProfile: profile.retrievalProfile,
guardrailMode: profile.guardrailMode,
});
await trackAiConfigExposure({
accountId: request.accountId,
flagKey: "support_answer_profile",
variation: profile.profile,
latencyMs: response.latencyMs,
fallbackUsed: response.fallbackUsed,
});
return response;
}
The important properties are stable: evaluate before the AI behavior runs, validate the returned profile, keep a fallback in code, and record exposure where the behavior actually ran.
The Risk-Control Matrix
Not every AI config needs the same process. A prompt wording change for an internal workflow is not the same as a retrieval-source expansion for customer data or an agent write-tool policy.
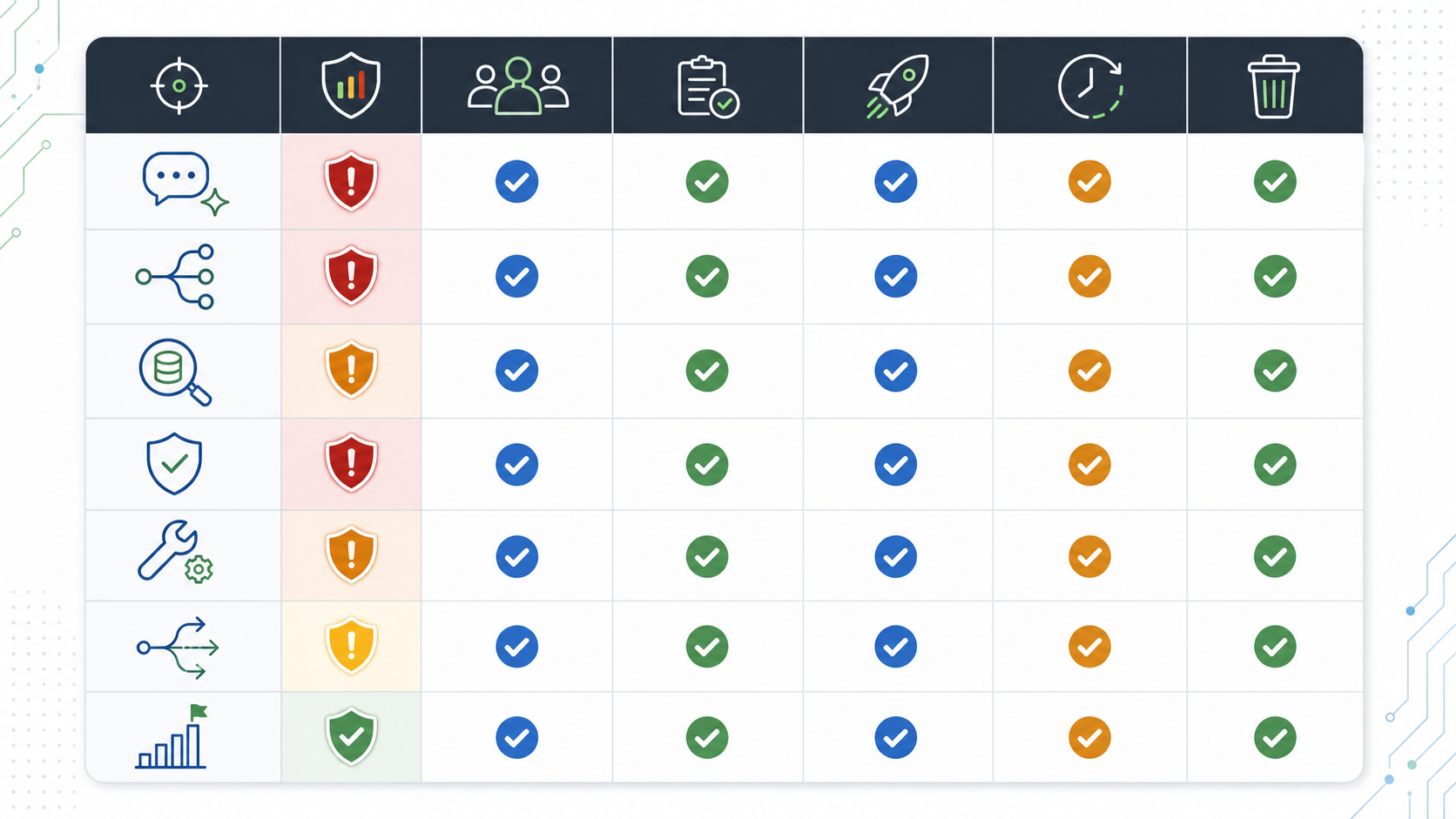
Use this matrix to set the management posture:
| Config type | Default owner | Evidence before expansion | Rollback design | Cleanup rule |
|---|---|---|---|---|
| Prompt profile | Feature owner or AI product owner | Offline checks, internal review, task outcome, correction rate | Return audience to baseline prompt profile | Remove losing prompt branch after decision. |
| Model route | AI platform owner | Quality signal, latency, cost, fallback rate, provider error rate | Return to baseline route or incident route | Remove temporary route if it is not durable. |
| Retrieval profile | Data or knowledge owner | Source review, citation quality, latency, leakage checks | Return to approved source scope | Retire unused indexes, filters, and profile references. |
| Guardrail threshold | Safety, support, or domain owner | False block rate, unsafe output review, escalation burden | Restore stricter threshold or human review | Keep as policy only if owner and review cadence are explicit. |
| Tool policy | Platform, security, or operations owner | Authorization review, side-effect test, audit record, approval burden | Reduce authority to read-only, approval-required, or off | Separate durable permission from temporary rollout flag. |
| Fallback mode | Operations owner | Drill result, customer impact, manual handoff capacity | Activate baseline, cached answer, handoff, or feature off | Keep durable incident fallback with periodic review. |
| Rollout rule | Release owner | Exposure integrity, primary metric, guardrails, segment health | Reduce percentage or target baseline to affected segment | Archive rollout flag after promotion or rollback. |
NIST's AI Risk Management Framework describes AI risk management as an ongoing practice across design, development, deployment, and use. A feature flag platform does not replace that broader governance work. It helps operationalize one important part of it: controlled exposure, observable evidence, rollback, audit, and cleanup for production AI behavior.
What To Keep Out Of AI Config
AI config management does not mean every boundary should become editable at runtime.
Keep these outside normal runtime config unless there is a reviewed reason:
- secrets, provider credentials, and signing keys;
- raw private prompts, private documents, or full trace payloads;
- authorization rules that should be enforced by the identity and access layer;
- schema definitions that application code must validate deterministically;
- regulated data-handling rules that cannot be relaxed by targeting;
- unbounded prompt or tool inputs that bypass review.
A runtime flag can decide which approved behavior is active for which audience. It should not become the only security boundary. For example, a flag may select approval_required_tools, but the service identity and tool authorization layer should still enforce what actions are possible.
How This Differs From Related AI Config Topics
AI config management overlaps with several adjacent topics, but the reader job is different.
| Related topic | Main question | How AI config management differs |
|---|---|---|
| Dynamic config for AI applications | How should the app change approved AI behavior at request time? | Management adds ownership, inventory, evidence, approval, lifecycle, and cleanup across all config surfaces. |
| Adjusting AI parameters on the fly | How do teams tune model parameters safely? | Parameter tuning is one subset of config management. |
| What one feature flag can control | Which AI surfaces can fit behind one flag? | Config management asks how the whole catalog is governed over time. |
| Approval flow for AI config changes | Who should approve which changes? | Approval is one stage in the broader management loop. |
| AI flag lifecycle management | How should AI feature flags move from creation to cleanup? | Config management focuses on the values and profiles those flags select. |
If the immediate question is implementation detail, start with dynamic config for AI applications. If the question is operating model, start here: define the config catalog, ownership, risk tiers, evidence loop, rollout controls, and cleanup policy.
A Practical Implementation Plan
For a team starting from scattered prompt files, environment variables, and model gateway settings, use this sequence.
1. Inventory Runtime AI Decisions
List every value that can change AI behavior without changing the surrounding product code:
- prompt profiles;
- model routes;
- retrieval profiles;
- guardrail modes;
- agent tool policies;
- fallback paths;
- rollout and experiment assignments;
- cost, timeout, token, and sampling budgets.
Mark where each value lives today: code, environment variable, prompt registry, model gateway, feature flag, database row, operations dashboard, or manual runbook.
2. Separate Stable Invariants From Release Decisions
Not every value belongs behind a flag. Keep stable invariants in code or policy. Move release decisions into runtime control only when the team needs targeting, staged exposure, measurement, rollback, or experimentation.
Good candidates for FeatBit control include candidate prompt profiles, model route changes, retrieval profile rollout, fallback modes, experiment variants, beta access, and incident controls.
3. Define Typed Profiles
Create schemas for profile types before exposing them broadly. A profile schema should make invalid combinations hard to serve.
type AiConfigProfile = {
profile: string;
owner: string;
promptProfile: string;
modelRoute: string;
retrievalProfile: string;
guardrailMode: "standard" | "strict" | "fallback_first";
toolPolicy: "none" | "read_only" | "approval_required";
fallback: "baseline" | "human_escalation" | "off";
};
Use the schema at the application boundary. If the returned profile is missing fields, has an unknown route, or violates a hard rule, fall back to the baseline.
4. Attach Rollout And Evidence Rules
For each managed config, record:
- first audience;
- excluded audiences or contexts;
- primary outcome;
- guardrail metrics;
- rollout stages;
- rollback trigger;
- cleanup condition.
FeatBit's targeting rules, percentage rollouts, and flag insights provide the control-plane primitives. FeatBit's Track Insights API supports sending variation and metric events for the evidence loop.
5. Review And Clean Up The Catalog
Schedule catalog review by config type:
| Review question | Why it matters |
|---|---|
| Does this config still change an active release decision? | Otherwise it may be stale runtime logic. |
| Is the fallback still valid? | Rollback fails if the old prompt, model, route, or source no longer works. |
| Are owners and evidence still current? | AI systems change faster than release memory. |
| Should this become durable config? | Some operational controls should remain, but with explicit ownership. |
| Can losing branches be removed? | Old prompt, model, retrieval, and tool paths add maintenance cost and incident confusion. |
FeatBit's feature flag lifecycle management model is the natural companion: temporary controls need expected end states, and durable controls need owners and review cadence.
Common Mistakes
Managing values but not decisions. A config dashboard can show every prompt and model route while still failing to answer who should receive a candidate, what evidence matters, and how rollback works.
Letting profiles drift without schemas. JSON config is useful only when the application validates it before use. Invalid or unknown profiles should fall back to a known behavior.
Changing AI config globally. Production AI behavior should usually move through internal targeting, canary rollout, segment expansion, or an experiment before broad exposure.
Treating exposure as proof. A rollout percentage controls blast radius. It does not decide whether the behavior improved quality, cost, latency, trust, or business outcome.
Keeping old config forever. Prompt candidates, model routes, retrieval profiles, and experiment variations should be promoted, segmented, operationalized, or removed after the decision.
Starting Checklist
Before standardizing AI config management, confirm:
- Every meaningful AI config has a key, owner, schema, baseline, and candidate state.
- Runtime profiles are validated before prompt assembly, model routing, retrieval, guardrail checks, or tool selection.
- Safe fallback behavior is available without the candidate profile.
- Targeting uses stable context such as account, user, region, workflow, plan, environment, or risk tier.
- Exposure events record the flag key, variation, profile, assignment unit, and rollout stage.
- Outcome events can be joined back to the served profile.
- High-risk configs have the right reviewer and approval evidence.
- Rollback can return an affected audience to baseline without redeployment.
- Temporary configs have cleanup conditions before broad rollout.
- Durable operational configs have owners and review cadence.
The bottom line: AI config management is how teams keep runtime AI behavior flexible without letting it drift. Store values in a controlled profile, serve them through targeted runtime flags, measure what actually ran, roll back quickly, and clean up after the decision.
Source Notes
- FeatBit product context: AI control layer, safe AI deployment, AI experimentation, AI governance, and feature flag lifecycle management.
- FeatBit implementation context: create flag variations, remote config, targeting rules, percentage rollouts, flag insights, audit logs, and Track Insights API.
- Standards context: OpenFeature's flag evaluation specification and evaluation context specification provide vendor-neutral language for typed evaluation, default values, and context-driven targeting.
- AI risk-management context: NIST's AI Risk Management Framework is cited as a general risk-management reference. This article applies the idea to runtime release controls and does not claim feature flags alone satisfy AI governance requirements.
- Related FeatBit reading: dynamic config for AI applications, adjust AI parameters on the fly, what AI configuration one feature flag can control, approval flow for AI config changes, and AI flag lifecycle management.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it shows AI config management as a runtime control plane. - Use
config-management-loop.pngnear the runtime management loop because it explains how contract, review, rollout, telemetry, rollback, and cleanup connect. - Use
risk-control-matrix.pngnear the risk-control matrix because it summarizes how config surfaces map to ownership, evidence, rollback, and cleanup.