AI-Generated Schemas Need Runtime Control
AI-generated schemas can speed up integration work, but they should not move directly from a model response into production behavior. A schema is a contract. If that contract controls structured output, tool input, event extraction, remote config, or an agent workflow, changing it is a release decision.
The safer pattern is to treat the schema as a versioned runtime contract: review it, validate it, expose it gradually behind a feature flag, measure failures and downstream outcomes, and roll back to a known baseline when the new contract breaks real traffic.
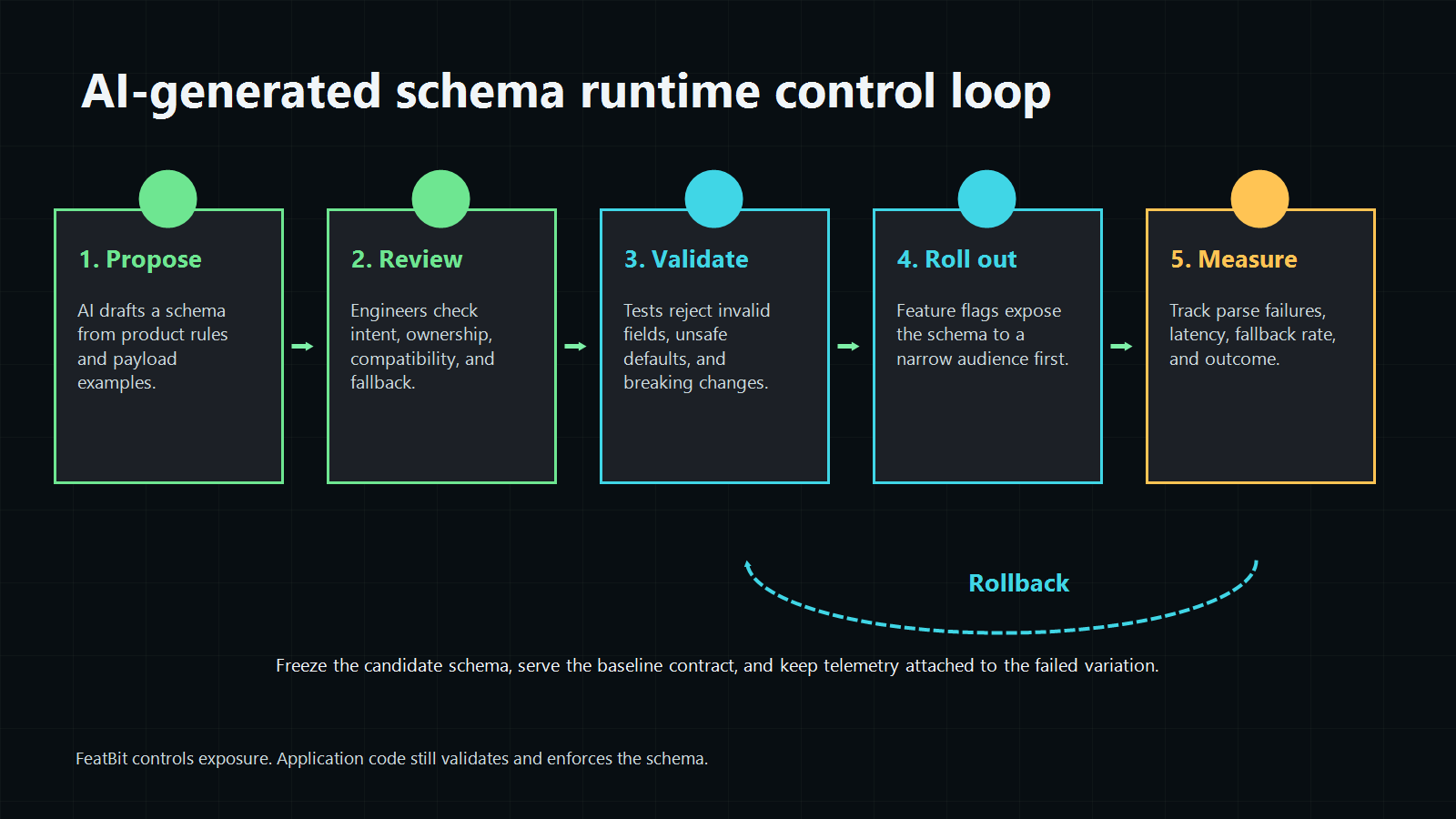
What AI-Generated Schemas Usually Mean
AI-generated schemas are schemas drafted or modified with AI assistance. In practice, that can include:
| Schema type | Example use | Production risk |
|---|---|---|
| Structured output schema | A model must return valid JSON for a support summary, lead score, or compliance note. | The model may produce fields the application cannot parse or trust. |
| Tool input schema | An agent chooses parameters before calling a search, billing, ticketing, or code tool. | A field change can alter side effects or bypass a review assumption. |
| Event schema | An AI extractor turns unstructured text into analytics or experiment events. | Downstream reports may silently change meaning. |
| Config profile schema | A model helps create JSON profiles for prompt, model, retrieval, guardrail, or fallback behavior. | Invalid combinations can become live runtime behavior. |
| API or integration schema | AI drafts request or response contracts for a service boundary. | Compatibility breaks can appear only after real clients send traffic. |
The phrase overlaps with structured outputs because AI platforms increasingly use schemas to constrain model responses. OpenAI's Structured Outputs guide describes using JSON Schema to make model outputs match a supplied structure. JSON Schema itself is a mature vocabulary for describing and validating JSON data, documented by the JSON Schema project.
That is useful. It is not enough. A valid schema can still be the wrong schema for one audience, one tenant, one workflow, or one downstream system.
The Real Risk Is Contract Drift
AI schema generation often feels like a developer productivity feature. The model reads requirements, examples, or payloads and proposes a schema faster than a human would write it by hand.
The risk appears later. Small schema changes can create production drift:
- A field becomes optional because the model saw a sample without it.
- A value enum expands beyond what downstream code accepts.
- A nested object changes shape and breaks stored prompts, parsers, or dashboards.
- A generated event schema changes metric meaning during an experiment.
- A tool input schema allows a parameter combination that the tool owner never reviewed.
- A fallback field exists in the schema, but the application does not actually handle it.
This is why AI-generated schemas belong in a release-control workflow. The question is not only "is this schema syntactically valid?" The question is "who should receive this schema, what evidence proves it works, and how quickly can we return to the previous contract?"
Define A Schema Release Contract
Before an AI-generated schema reaches production traffic, define a compact release contract. The exact format can vary, but the contract should be readable by product engineers, platform teams, reviewers, and future AI coding agents.
schema_release:
key: support_summary_schema
owner: support_platform
baseline_version: v3
candidate_version: v4_citation_fields
generated_from:
- product_requirements
- accepted_payload_examples
assignment_unit: account
first_audience: internal_support_users
validation:
- json_schema_validation
- backward_compatibility_check
- sample_payload_replay
primary_metric: successful_summary_parse_rate
guardrails:
- downstream_retry_rate
- support_agent_correction_rate
- p95_latency
- fallback_rate
rollback: serve_baseline_v3_schema
cleanup: promote_v4_or_delete_candidate_after_decision
This contract separates generation from release. AI can help draft the schema. Humans and automated checks decide whether it is an acceptable contract. Feature flags decide who receives it in production.
Validate More Than Syntax
Schema validation should start with syntax, but production readiness needs a wider gate.
| Check | What it catches |
|---|---|
| JSON Schema validation | Invalid types, missing required fields, unsupported values, and malformed examples. |
| Backward compatibility | Removed fields, stricter requirements, enum changes, or renamed paths that older consumers still need. |
| Sample replay | Whether real historical payloads still pass and produce equivalent downstream behavior. |
| Contract tests | Whether the parser, tool adapter, event pipeline, or API client still behaves correctly. |
| Fallback test | Whether the application returns to the baseline schema when the candidate is off, invalid, or rolled back. |
| Observability test | Whether telemetry includes schema version, flag variation, assignment unit, and failure reason. |
For AI systems, the validation boundary should sit before the behavior runs. If a structured output schema changes how a model responds, validate the schema and fallback before prompt assembly or response parsing. If a tool input schema changes what an agent may call, validate it before the execution boundary.
OpenFeature's evaluation context specification is useful vendor-neutral language here. The evaluation context is what lets a flag decision vary by user, account, tenant, environment, region, workflow, or risk tier instead of serving one schema to everyone.
Roll Out Schemas Like Product Behavior
An AI-generated schema should usually move through staged exposure.
- Keep the baseline schema in code or a trusted registry.
- Add the candidate schema as a named variation or referenced profile.
- Evaluate the schema-selection flag server-side before the AI behavior, parser, tool call, or event pipeline runs.
- Target internal users, test accounts, or shadow traffic first.
- Expand to a beta segment or small percentage only when validation and telemetry are healthy.
- Roll back the affected audience to baseline when parse failures, fallback rate, latency, correction rate, or downstream errors cross the threshold.
- Promote the winning schema or remove the candidate branch after the decision.
FeatBit's AI control layer describes this broader pattern: every AI decision point becomes a runtime control surface. For schema releases, the control surface is the contract version the application accepts, emits, or asks the model to follow.
FeatBit can support the rollout layer through multivariate flag variations, targeting rules, percentage rollouts, flag insights, and the Track Insights API. The application still owns validation and enforcement.
A Practical Implementation Shape
The implementation should make the fallback obvious. This TypeScript example is intentionally simplified. It shows the contract placement, not a vendor-specific SDK wrapper.
type SchemaVersion = "support_summary_v3" | "support_summary_v4";
type SchemaSelection = {
version: SchemaVersion;
schema: unknown;
fallbackVersion: SchemaVersion;
};
const baselineSelection: SchemaSelection = {
version: "support_summary_v3",
schema: supportSummarySchemaV3,
fallbackVersion: "support_summary_v3",
};
async function summarizeSupportCase(request: SupportRequest) {
const context = {
keyId: request.accountId,
plan: request.plan,
region: request.region,
workflow: "support_summary",
};
const selected = await flags.jsonVariation<SchemaSelection>(
"support-summary-schema",
context,
baselineSelection
);
const schemaSelection = validateSchemaSelection(selected)
? selected
: baselineSelection;
const response = await callModelWithStructuredOutput({
schema: schemaSelection.schema,
input: request.caseText,
});
const parsed = parseWithFallback({
response,
schema: schemaSelection.schema,
fallbackSchema: baselineSelection.schema,
});
await trackSchemaOutcome({
accountId: request.accountId,
flagKey: "support-summary-schema",
schemaVersion: schemaSelection.version,
parseOk: parsed.ok,
fallbackUsed: parsed.fallbackUsed,
});
return parsed.value;
}
Three details matter more than the exact SDK call:
- The schema decision happens before the AI request or parser depends on it.
- The baseline schema is available even when the flag service or candidate value fails.
- Telemetry records the schema version that actually served the request.
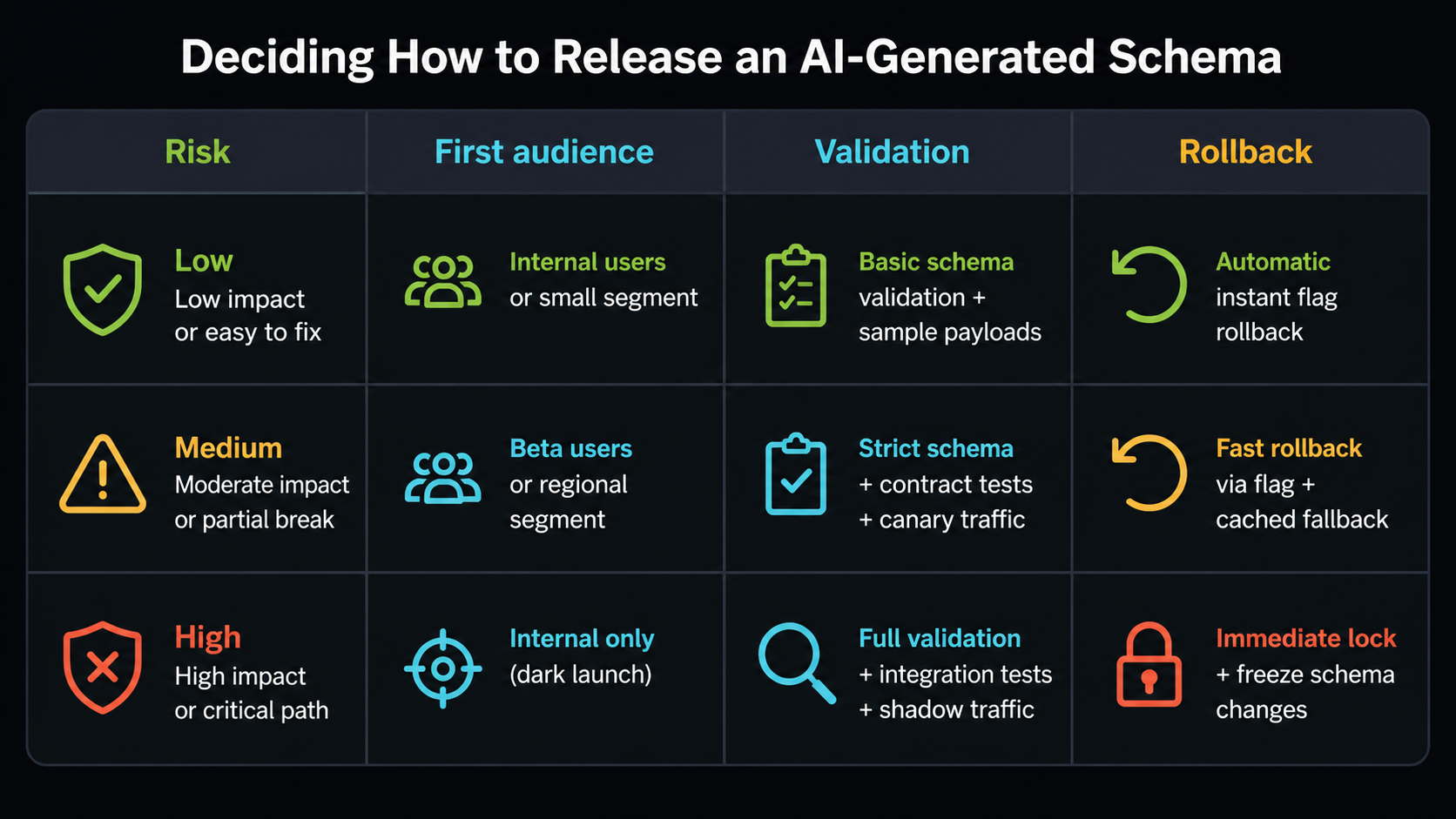
When A Schema Belongs Behind A Flag
Not every schema should be runtime configurable. Stable security boundaries, compliance rules, and low-level invariants often belong in code and policy. Put a schema behind a flag when the team needs targeted exposure, measurement, rollback, or experimentation.
| Situation | Flag the schema? | Reason |
|---|---|---|
| New structured output shape for one workflow | Yes | Start with internal users or one segment before broad release. |
| Tool input schema grants a new side-effect path | Yes, with strict approval | Roll out tool authority separately from prompt or model changes. |
| Event schema changes experiment metrics | Yes | Prevent metric drift by tying exposure to schema version. |
| API contract used by external clients | Usually not as a loose runtime switch | Use formal versioning, compatibility review, and client migration. A flag may still control which internal audience receives the new contract. |
| Safety or authorization invariant | No | Keep hard boundaries outside feature flags. A flag can choose approved behavior, not define the only security control. |
| Temporary generated candidate for evaluation | Yes | Treat it as a release hypothesis with a cleanup rule. |
This boundary keeps feature flags from becoming a hidden schema registry. FeatBit should control exposure and release decisions. Application code, tests, and schema tooling should still validate and enforce the contract.
How This Differs From AI Config Management
AI config management asks how prompts, model routes, retrieval profiles, guardrails, tools, fallbacks, rollout rules, and experiments are managed as runtime behavior. AI-generated schemas are narrower. They focus on the contracts that make AI output, tool calls, events, or config profiles machine-readable.
The two topics connect when a config profile itself is JSON. A schema can validate the profile. A feature flag can decide which profile version is active. Telemetry can show which version ran. Lifecycle rules can remove the losing candidate after the decision.
For the broader operating model, see FeatBit's guide to AI config management and the implementation guide for dynamic config for AI applications. For schema releases, keep the promise tighter: prevent generated contracts from drifting into production without controlled exposure and evidence.
Pitfalls To Avoid
Treating a valid schema as a safe schema. Validation proves shape, not product correctness. You still need compatibility, fallback, rollout, and outcome evidence.
Letting AI generate the fallback too late. A fallback should be a known baseline, not another candidate created during an incident.
Changing schema and prompt at the same time without attribution. If the prompt and schema both change, telemetry should record both versions. Otherwise the team will not know which change caused the result.
Using one global schema switch. A schema that is safe for internal support users may be unsafe for regulated accounts, high-volume tenants, or workflows with irreversible side effects.
Leaving candidate schemas alive forever. Temporary generated schemas become hidden product logic if they are not promoted, removed, or documented after the release decision.
Bottom Line
AI-generated schemas are useful because they compress the time from requirement to machine-readable contract. That speed is valuable only when the release system keeps up.
Treat every important generated schema as a runtime contract with an owner, baseline, candidate, validation gate, first audience, metric plan, rollback path, and cleanup decision. Use feature flags to control exposure. Use application code to validate and enforce the contract. Use telemetry to decide whether the schema should expand, pause, roll back, or disappear.
That is the FeatBit perspective: AI can help create the schema, but release-decision infrastructure decides when the schema becomes production behavior.
Source Notes
- AI platform context: OpenAI's Structured Outputs guide is used for the category pattern of making model outputs follow a supplied JSON Schema. This article does not claim that Structured Outputs alone solves release control.
- Schema validation context: the JSON Schema getting started guide is used for the general role of JSON Schema in describing and validating JSON data.
- Flag evaluation context: OpenFeature's evaluation context specification is used as vendor-neutral language for context-driven flag evaluation and targeting.
- FeatBit implementation context: create flag variations, targeting rules, percentage rollouts, flag insights, Track Insights API, and feature flag lifecycle management support the workflow described here.
- Related FeatBit reading: AI control layer, safe AI deployment, AI config management, and dynamic config for AI applications.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it shows AI-generated schemas moving through validation, staged rollout, observability, and rollback. - Use
schema-control-loop.pngnear the opening because it summarizes the release loop in crawlable body context. - Use
rollout-matrix.pngnear the rollout section because it gives readers a visual risk model for first audience, validation depth, and rollback posture.