Approval Flow for AI Model Changes: From Eval to Rollback
An approval flow for AI model changes decides when a candidate model route is allowed to move from offline evidence to real users, which reviewer owns the risk, how exposure expands, and how the team rolls back if quality, cost, latency, safety, or business guardrails fail.
Treat model approval as a release decision, not only a registry status. A model can be approved for testing, approved for internal exposure, approved for a small canary, or approved as the default route. Those are different decisions. Each one needs evidence, scope, rollback, and audit context.
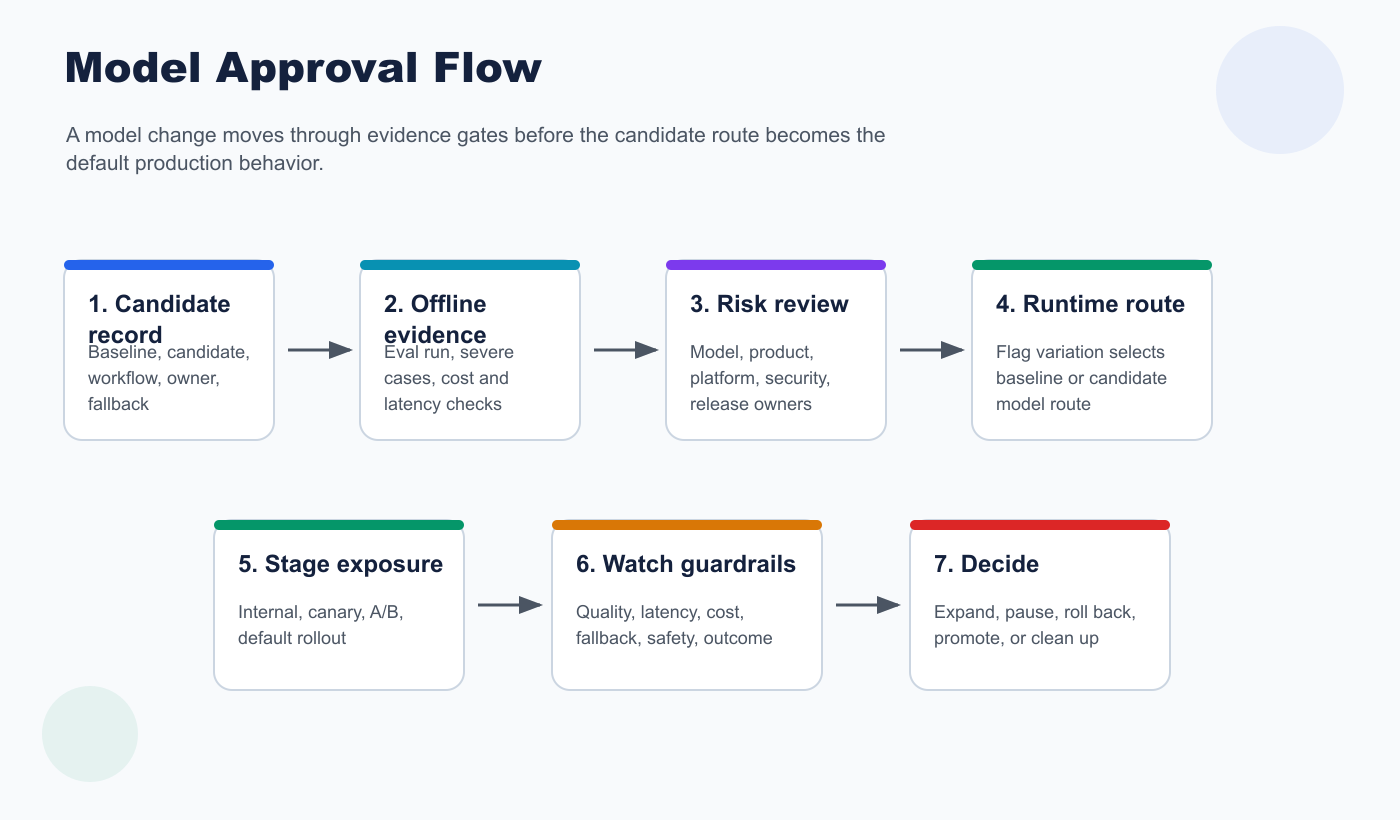
What A Model Change Approval Flow Must Decide
Model changes create risk across more than model quality. A newer model may improve reasoning on one workflow while changing latency, cost, failure modes, data boundary, fallback behavior, or support workload in another.
The approval flow should answer six questions before production exposure expands:
| Approval question | Why it matters |
|---|---|
| What exactly is changing? | The model name alone may hide prompt, retrieval, parameter, provider, timeout, and fallback changes. |
| Which workflow is affected? | A support summarizer, search ranker, coding assistant, and billing classifier need different evidence. |
| Who owns the release decision? | The model platform owner may not own customer impact or business metrics. |
| What evidence qualifies the candidate? | Offline evals, regression tests, shadow runs, and human review answer different questions. |
| Which audience sees it first? | Approval should include target segment, percentage, region, environment, and exclusion rules. |
| How does rollback happen? | The team should be able to return traffic to the baseline model route without redeploying. |
AWS SageMaker Model Registry is a useful category reference because it supports model versions, metadata, lineage, lifecycle staging, approval status, production deployment, and CI/CD automation. That kind of registry can store model readiness. It does not by itself decide every runtime exposure rule for every product segment. The release approval still needs a control plane around who sees the model now.
The Approval Boundary For Model Changes
Do not require the same approval path for every model edit. Route the approval by production effect.
| Change tier | Model change examples | Approval posture |
|---|---|---|
| Low | Update a non-production model alias, add eval cases, change a local test model | Normal review and owner record |
| Medium | Change a model route for internal users, adjust timeout, add a fallback candidate | Model owner approval and controlled exposure |
| High | Switch provider, change default model family, alter cost or latency profile, expose candidate to customers | Product plus AI platform approval, guardrails, staged rollout, rollback test |
| Restricted | Model touches regulated data, financial decisions, permission decisions, legal terms, or irreversible actions | Security, policy, or domain review before any live exposure |
NIST's AI Risk Management Framework is voluntary guidance, not a certification shortcut. It is still useful here because it frames AI risk work across design, development, use, and evaluation. For model changes, translate that into a practical sequence: map the changed behavior, measure candidate evidence, manage exposure, and keep the decision governable.
A Seven-Step Approval Flow For Model Changes
The useful approval flow is not a single "approve model" button. It is a sequence of gates that make the model safer to compare, expose, expand, or reject.
1. Create A Candidate Model Record
Start with a compact record that explains the candidate route.
Include:
- model name, provider, version, route key, owner, and affected workflow;
- baseline model route and candidate model route;
- prompt version, retrieval profile, tool policy, parameters, timeout, and fallback if they changed;
- expected product improvement;
- expected cost, latency, safety, data, or support risk;
- first eligible audience;
- rollback value and owner.
The approval record should make route bundling explicit. If model B also uses a new prompt and retrieval index, approve it as a candidate route, not as a pure model swap.
2. Attach Offline Evidence Before Live Exposure
Offline evidence qualifies a candidate for exposure. It does not prove the model should become the default.
Useful offline evidence includes:
- regression evals against known severe failures;
- task-quality evals for the affected workflow;
- adversarial or long-tail cases that reflect real input risk;
- latency, provider error, and cost checks;
- human review for samples where automated grading is weak;
- compatibility checks for response schema, citations, tool calls, and fallback behavior.
OpenAI's evals documentation describes evals as needing test data plus graders or testing criteria. That is a practical shape for model approval evidence: the reviewer should know which dataset, scorer, threshold, and candidate run they are approving.
3. Route The Review To The Right Owner
Model approval often fails when one group approves a technical metric while another group owns the customer outcome.
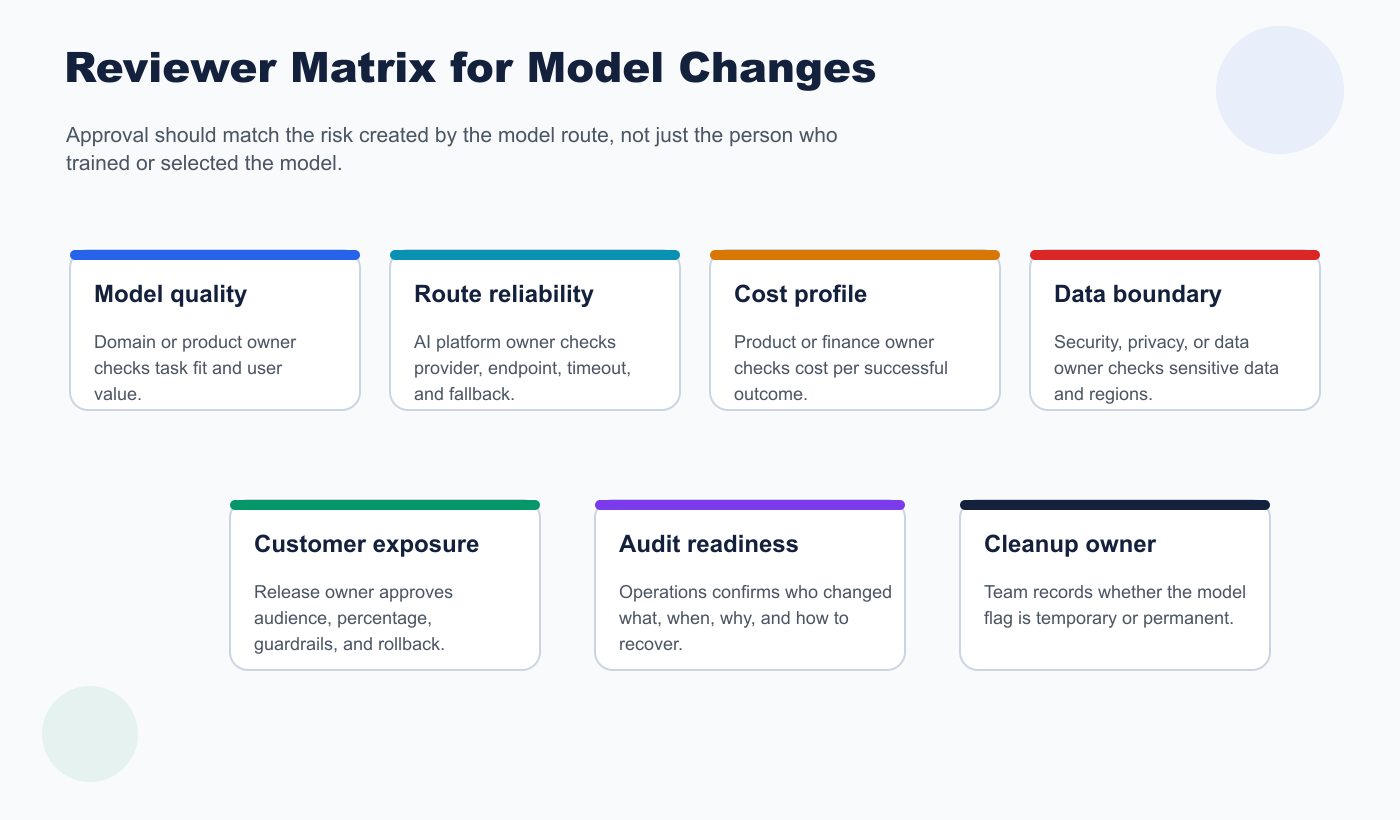
Use this reviewer map:
| Risk trigger | Required reviewer | Approval focus |
|---|---|---|
| Model quality or task fit | Domain owner or product owner | The candidate improves the workflow that matters. |
| Provider, endpoint, routing, or fallback change | AI platform owner | The route is reliable, observable, and reversible. |
| Cost profile changes | Product or finance owner | The cost per successful outcome is acceptable. |
| Latency or availability changes | Engineering or operations owner | Service targets and incident paths remain acceptable. |
| Sensitive data or region boundary changes | Security, privacy, or data owner | The route respects data handling requirements. |
| Customer-visible expansion | Release owner | The first audience, guardrails, and rollback path are approved. |
The same person can fill more than one role in a small team. The important habit is separation of concerns: the person approving model quality is not automatically approving production blast radius.
4. Approve A Runtime Route, Not A Static Default
The approved model route should be represented as a runtime decision. That gives the team targeting, staged exposure, audit history, rollback, and a clean way to compare candidate behavior.
A model route flag can use string or JSON variations:
model_change:
flagKey: support_answer_model_route
owner: support-ai-platform
baseline:
model: support-model-a
promptVersion: support-v3
retrievalProfile: public-docs
fallback: baseline-search
candidate:
model: support-model-b
promptVersion: support-v3
retrievalProfile: public-docs
fallback: baseline-search
approval:
status: approved-for-canary
reviewers:
- support-product-owner
- ai-platform-owner
evidence:
- offline-eval-run-2026-06-11
- rollback-test-passed
exposure:
firstAudience: internal-support
nextAudience: five-percent-low-risk-accounts
excluded:
- regulated-region
- enterprise-legal-review
rollback:
defaultVariation: baseline
FeatBit's targeting rules and percentage rollouts are the practical primitives for this kind of route approval. The application evaluates the route before the model call, then logs the evaluated variation with the model output and downstream outcome.
5. Stage Exposure By Evidence
The approval flow should name the next gate before traffic starts.
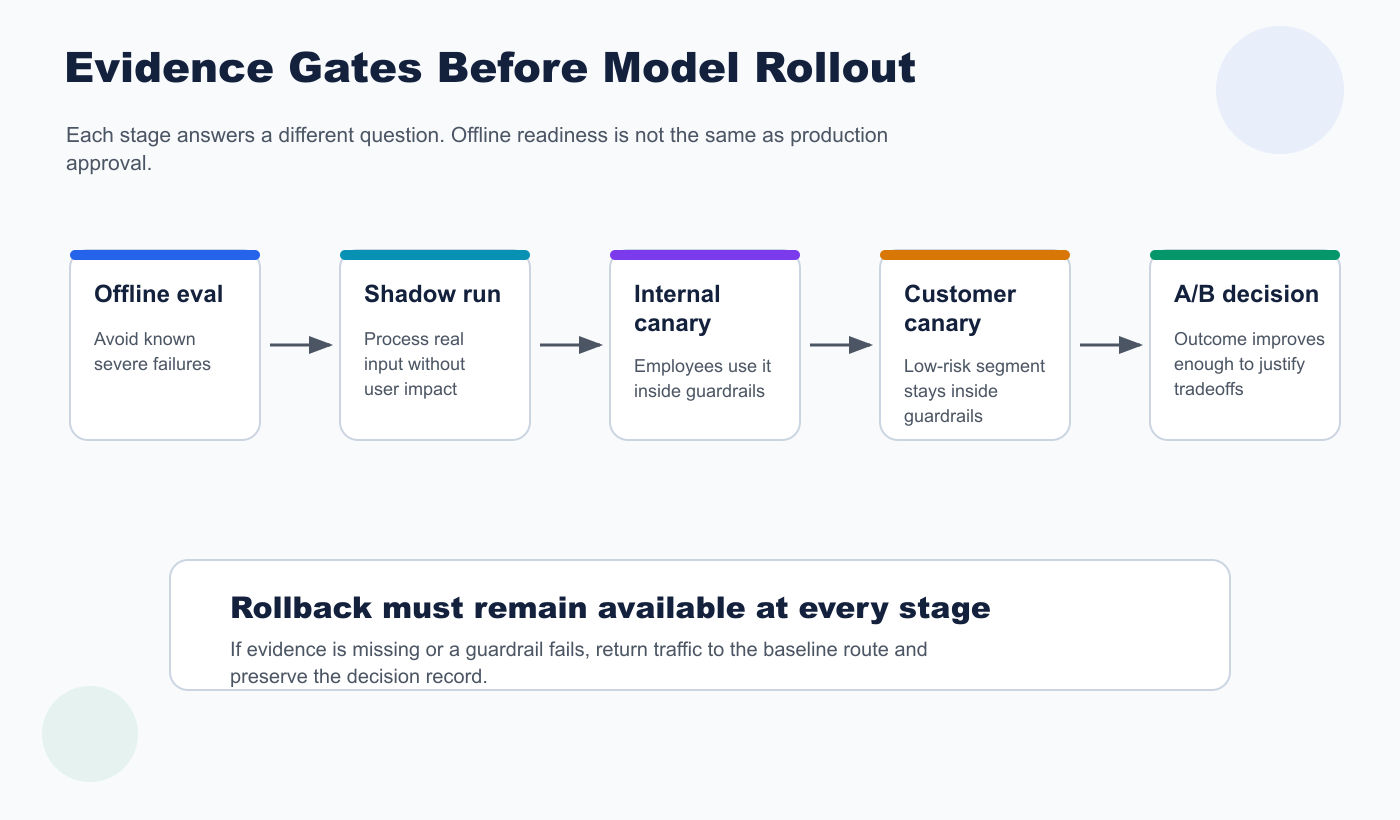
Common stages:
| Stage | Evidence goal | Release decision |
|---|---|---|
| Offline eval | Candidate avoids known severe failures and meets task rubric | Eligible for non-user-facing validation |
| Shadow run | Candidate can process real input shape without affecting users | Eligible for internal or narrow live exposure |
| Internal canary | Employees or test accounts can use the route without severe guardrail failures | Eligible for limited customer canary |
| Customer canary | Low-risk segment stays within quality, latency, cost, support, and safety guardrails | Expand, pause, or revise |
| A/B comparison | Candidate improves the product outcome enough to justify tradeoffs | Promote, keep testing, or reject |
| Default rollout | Candidate is accepted as the normal route | Clean up temporary controls or document permanent route control |
FeatBit scheduled flag changes can help plan progressive rollout steps once approval exists. Do not schedule expansion before the evidence gate is clear. Scheduled release is useful only when the stop conditions and review owners are already known.
Guardrails That Should Block Expansion
Model changes should have one primary improvement goal and several guardrails. Approval should pause when a guardrail is missing or breached.
Use guardrails such as:
- quality review score or model-graded task score;
- accepted answer, resolved case, or successful task completion;
- p95 latency and provider error rate;
- fallback rate and retry rate;
- estimated cost per successful outcome;
- human edit rate, escalation rate, or support complaint rate;
- unsafe output report, policy violation, or data-boundary signal;
- segment-specific harm for priority accounts, regions, or workflows.
The FeatBit Track Insights API is relevant when the team needs to connect evaluated variations with custom metric events. For model changes, the exposure event should be emitted when the model route actually runs, not when a page loads or a candidate is merely eligible.
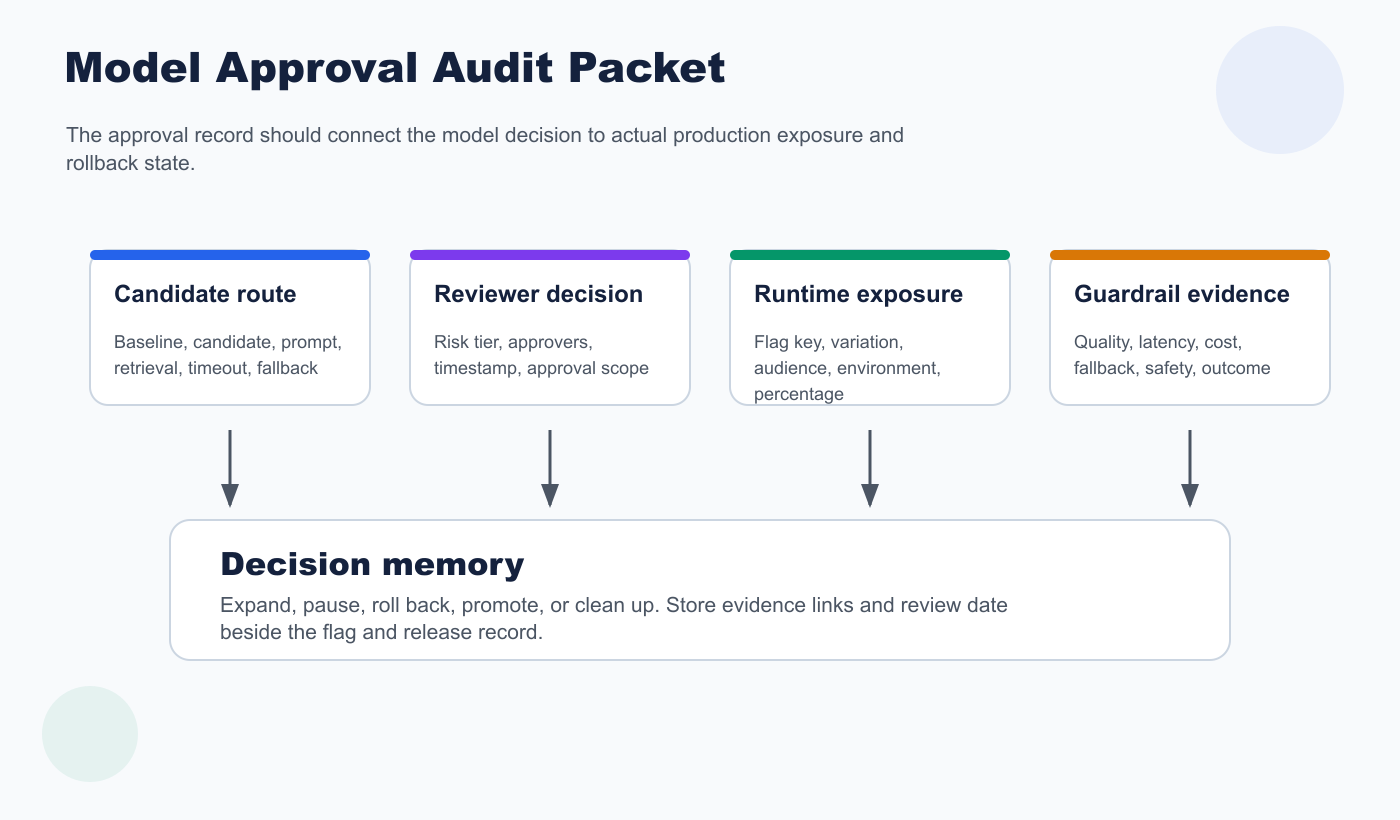
What The Approver Needs To See
A useful approval card should be short enough to review quickly and specific enough to reconstruct later.
Minimum fields:
| Field | Why it matters |
|---|---|
| Baseline and candidate route | Shows exactly what can change at runtime. |
| Workflow and audience | Prevents a model approved for one context from spreading to another. |
| Evidence links | Lets reviewers inspect evals, shadow results, canary data, or human review. |
| Guardrails and thresholds | Defines what would block expansion or force rollback. |
| Rollback value | Shows the exact route to serve when the candidate is stopped. |
| Required reviewers | Separates model quality, platform, product, security, and release decisions. |
| Audit source | Shows where the approval and flag changes can be reconstructed. |
| Cleanup or permanence rule | Prevents temporary model flags from becoming unexplained routing logic. |
FeatBit audit logs track changes made to feature flags in an environment. FeatBit IAM helps restrict who can change projects, environments, metrics, teams, and feature flags. Approval is still a team process, but the runtime control should make changes visible and permissioned.
Where FeatBit Fits
FeatBit should sit around the model registry, eval system, observability stack, and application service as the runtime release-control layer.
Use a model registry or deployment platform to track model artifacts, versions, lineage, and deployment endpoints. Use eval systems to qualify candidate behavior. Use observability to inspect latency, errors, cost, and outcomes. Use FeatBit to decide which approved model route is active for a specific environment, account, user, region, workflow, risk tier, or rollout stage.
In practice, FeatBit helps the model approval flow by supporting:
- named model-route flags and variations;
- internal, beta, segment, region, and percentage targeting;
- staged rollout and rollback without redeploying the application;
- audit history for flag and targeting changes;
- IAM policies for production control;
- exposure and metric events for release decisions;
- lifecycle ownership so temporary model-release flags are reviewed after the decision.
For the broader operating model, FeatBit's AI control layer, safe AI deployment, AI governance and risk control, and feature flag lifecycle management pages expand the same release-control pattern.
Common Failure Modes
Approving the model artifact but not the route. The route may include prompt, retrieval, timeout, provider, and fallback behavior. Approve the bundle users will actually experience.
Skipping rollback rehearsal. If the team cannot prove the baseline route still works, approval is incomplete.
Treating offline evals as launch authority. Offline evals can qualify a model for exposure. They do not prove business impact under real users.
Letting cost approval happen after rollout. Cost should be a guardrail before traffic expands, especially when model choice changes token use, provider pricing, retry behavior, or human review load.
Using one approver for every risk. Platform reliability, product value, data handling, and customer support risk often need different reviewers.
Leaving model test flags behind. After the release decision, remove temporary branches or document the flag as a permanent operational model route.
Starting Checklist
Before approving a model change for production exposure, confirm:
- The baseline route, candidate route, owner, workflow, and first audience are recorded.
- The candidate has evidence appropriate to the risk tier.
- Reviewers match the risk created by the model route.
- The route is controlled at runtime through a flag or equivalent release control.
- Exposure starts with a named audience or percentage.
- Guardrails cover quality, latency, cost, fallback, safety, and business outcome.
- Rollback returns traffic to a known baseline route without redeploying.
- Audit records connect approval, flag variation, rollout stage, reviewer identity, and evidence.
- The cleanup or permanence decision is scheduled before broad rollout.
The bottom line: approval for model changes should move a candidate through evidence gates, not stamp a model as globally safe. Approve the model route, approve the audience, approve the rollback path, and keep the evidence close enough that the next reviewer can understand why the model changed.
Source Notes
- External model lifecycle context: AWS SageMaker AI Model Registry documentation is used as a category reference for model versions, metadata, lineage, lifecycle staging, approval status, deployment, and CI/CD automation.
- AI risk context: NIST AI Risk Management Framework is cited as voluntary risk-management guidance for design, development, use, and evaluation. This article does not make compliance claims.
- Eval evidence context: OpenAI evals documentation is cited for the practical shape of test data and graders in model evaluation.
- FeatBit implementation sources: targeting rules, percentage rollouts, scheduled flag changes, audit logs, IAM, and Track Insights API support the operating model described here.
- Related FeatBit reading: model A/B testing, A/B testing AI models for business impact, AI governance and risk control, and AI flag owner review workflow.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes model approval as a sequence from evidence to runtime release control. - Use
model-approval-flow.pngnear the opening because it shows the end-to-end approval path. - Use
model-reviewer-matrix.pngnear the reviewer section because it maps model risk to approval ownership. - Use
model-evidence-gates.pngnear the rollout section because it separates offline readiness from live release decisions. - Use
model-approval-audit-packet.pngnear the audit section because it shows which fields make model approval reconstructable.