Vendor-Agnostic AI Feature Flags: Design Runtime Control Without Lock-In
Vendor-agnostic AI feature flags are feature flag contracts that keep AI release decisions portable across model providers, gateways, SDKs, and flag platforms. The goal is not to make every vendor interchangeable overnight. The goal is to keep your application code from hard-coding one provider's rollout model, one gateway's experiment logic, or one platform's flag shape into every AI decision.
For AI teams, that matters because the runtime surface is changing quickly. A prompt, model route, retrieval profile, guardrail mode, or agent tool policy may need to move from one provider to another, from a hosted flag platform to a self-hosted control plane, or from custom code to a standard API. If the release contract is vendor-specific, every migration becomes an application refactor. If the contract is stable, the team can change the control plane behind it without rewriting the AI product path.
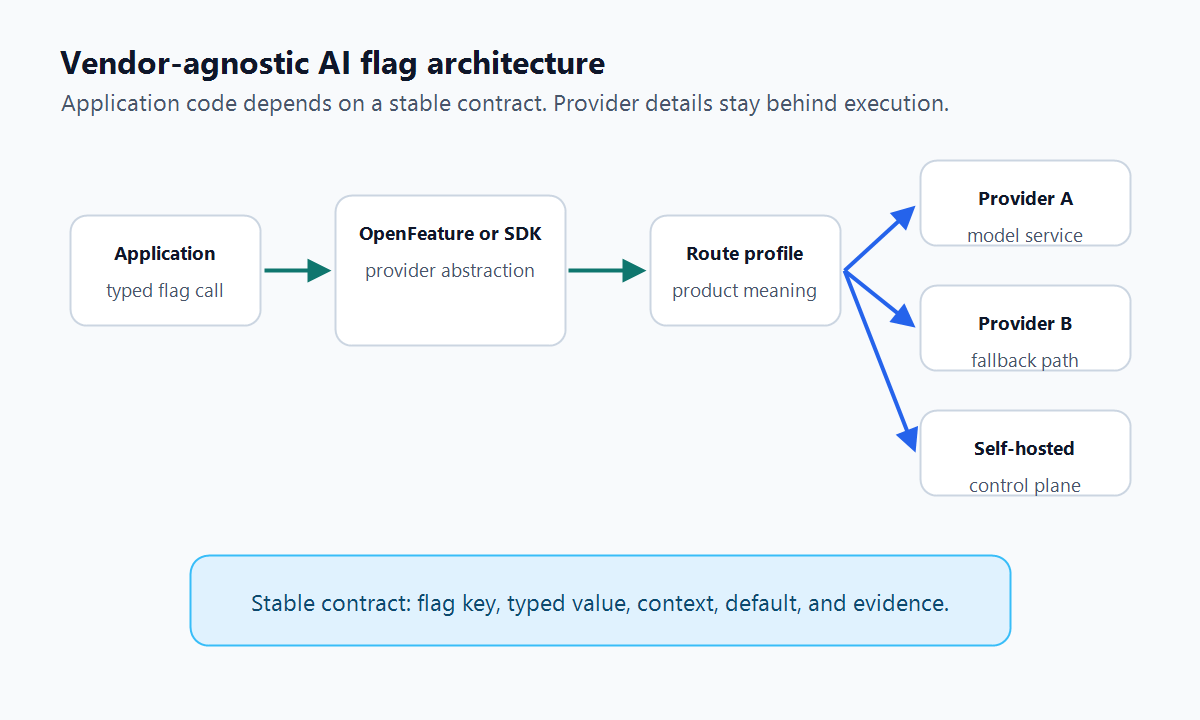
What Vendor-Agnostic Means For AI Flags
Vendor-agnostic does not mean "do not use a vendor." It means the application depends on a small, stable flag contract instead of on provider-specific behavior scattered through the codebase.
In practice, the contract should answer five questions:
| Contract question | AI example | Why it protects portability |
|---|---|---|
| What decision is being made? | support_assistant_route |
The release decision has a durable name outside any vendor UI. |
| What type is returned? | string or JSON route profile | Application code can validate the shape before running AI behavior. |
| What context decides eligibility? | account, user, region, workflow, risk tier | Targeting logic stays explicit instead of hidden inside the model gateway. |
| What fallback runs if evaluation fails? | baseline prompt and model route | The product keeps a safe default when the control plane is unavailable. |
| What evidence is recorded? | variation, route, latency, cost, quality, outcome | Migration does not break the release learning loop. |
OpenFeature is the clearest public standard for this direction. Its homepage describes OpenFeature as a vendor-agnostic API for feature flagging that can work with commercial tools, open-source tools, or in-house systems, and it explicitly frames standardization as a way to avoid code-level lock-in. Its flag evaluation specification also defines typed evaluation, evaluation context, default values, detailed evaluation metadata, providers, and domains. Those ideas map directly to AI release control because the application needs a stable decision point before it chooses a prompt, model, retrieval profile, or tool mode.
Why AI Makes Portability More Important
Traditional feature flags often decide whether a UI, endpoint, or workflow is visible. AI feature flags can decide how the system behaves at runtime:
- which model provider or model version receives the request;
- which prompt profile, retrieval profile, or reranker runs;
- whether an agent can observe, draft, call a tool, or require approval;
- which guardrail mode, timeout, budget, or fallback path applies;
- which experiment variation a user, account, conversation, or workflow receives.
Those decisions sit close to cost, quality, latency, safety, and user trust. They also sit close to vendor dependencies. If a flag returns a raw provider model name everywhere in the codebase, changing providers is difficult. If the flag returns a named route profile such as support_balanced_v2, the application can map that profile to whichever model gateway, provider, or fallback policy is approved today.
This is why FeatBit treats AI feature flags as release-decision infrastructure, not just remote settings. The durable object is the release decision: who should receive the candidate AI behavior, under what guardrails, with what rollback path, and with what evidence. The vendor implementation should be replaceable behind that contract.
Use A Route Profile, Not Provider-Specific Knobs
The most common portability mistake is putting provider details directly into every flag value:
{
"provider": "vendor_a",
"model": "model-x-2026-06",
"temperature": 0.7,
"topP": 0.9,
"retrievalK": 12
}
That looks flexible, but it creates a migration problem. The application now knows a provider-specific vocabulary, every reviewer has to understand every knob, and the flag can produce combinations the team never validated together.
Prefer a typed route profile:
{
"route": "support_balanced_v2",
"promptProfile": "citation_first_v3",
"retrievalProfile": "verified_docs_v2",
"guardrailMode": "standard",
"fallbackRoute": "support_baseline_v1"
}
The AI service or model gateway owns the provider mapping. The flag owns the release decision. That separation keeps portability practical:
| Layer | Owns | Should avoid |
|---|---|---|
| Feature flag | eligibility, variation, rollout, fallback choice, audit, exposure | secrets, raw prompts, provider credentials |
| Application service | request context, authorization, business logic, exposure event | hidden rollout logic |
| Model gateway | provider calls, retries, token budgets, prompt assembly, provider fallback | product release decisions no one can audit |
| Observability system | traces, metrics, logs, quality and outcome signals | becoming the only place a release decision is visible |
FeatBit's AI control layer framing fits this boundary: runtime flags control exposure and behavior selection, while the AI service executes the selected route and observability systems provide evidence.
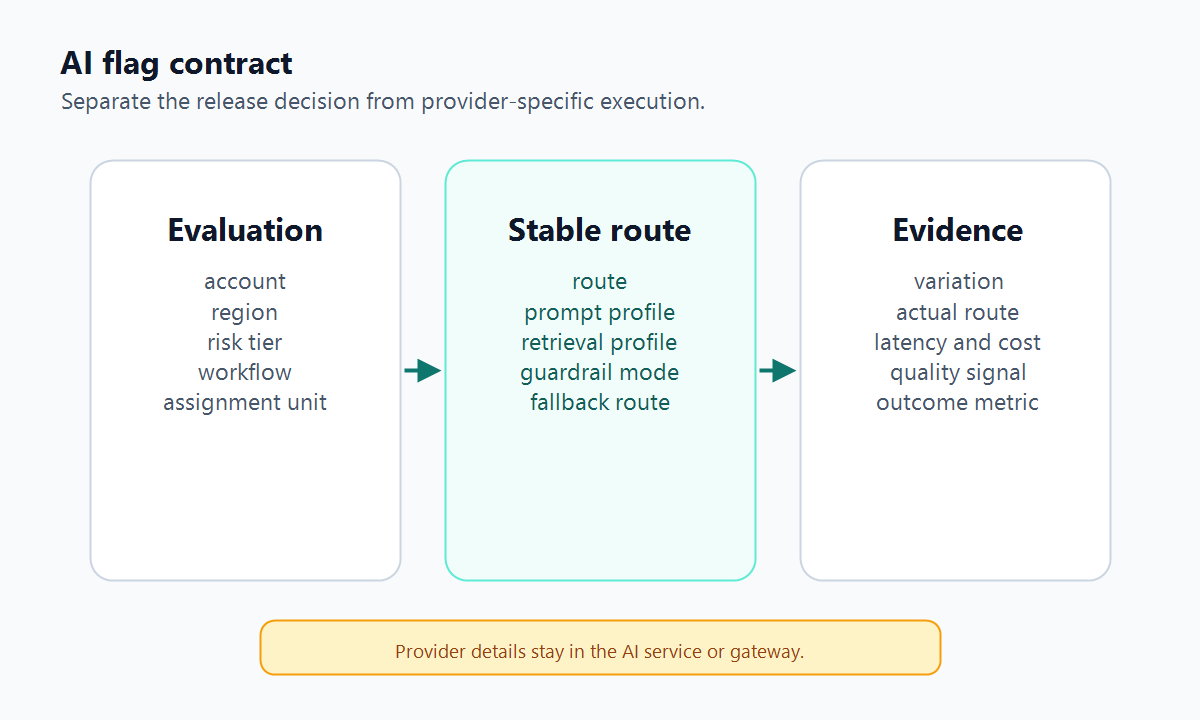
Design The Evaluation Contract
A vendor-agnostic AI flag should be boring at the call site. The application asks for a typed decision, passes the context that matters, receives a safe default if evaluation fails, and records what actually ran.
type SupportAssistantRoute = {
route: 'support_baseline_v1' | 'support_balanced_v2' | 'support_strict_v2';
promptProfile: string;
retrievalProfile: string;
guardrailMode: 'standard' | 'strict' | 'fallback_first';
fallbackRoute: string;
};
const defaultRoute: SupportAssistantRoute = {
route: 'support_baseline_v1',
promptProfile: 'baseline_v4',
retrievalProfile: 'verified_docs_v1',
guardrailMode: 'standard',
fallbackRoute: 'support_baseline_v1',
};
const route = await flags.getObjectValue<SupportAssistantRoute>(
'support_assistant_route',
defaultRoute,
{
targetingKey: account.id,
accountTier: account.tier,
region: account.region,
workflow: 'support_chat',
riskTier: account.riskTier,
}
);
This pattern stays portable because the application code depends on:
- a stable flag key;
- a typed return shape;
- an evaluation context;
- a default behavior;
- a separate execution layer that maps the route to provider calls.
OpenFeature's flag evaluation model is useful here because it standardizes the idea of typed flag calls with a key, default value, and evaluation context. It does not design your AI route for you. You still need a product-specific contract that names the AI behavior and the evidence required to release it.
Keep Experiment Evidence Portable Too
Portability fails if only the flag call is abstracted. AI release decisions need evidence, and evidence can become vendor-locked just as quickly as SDK calls.
For each AI flag, record at least:
- flag key and variation;
- route profile actually executed;
- user, account, conversation, request, or workflow assignment unit;
- prompt profile, retrieval profile, guardrail mode, and fallback status when relevant;
- latency, error, cost, blocked-output, fallback, and escalation guardrails;
- the primary product outcome used for the release decision.
OpenTelemetry's generative AI semantic conventions are relevant because they give teams a shared vocabulary for instrumenting AI system behavior across providers and frameworks. You do not need to adopt every attribute to be vendor-agnostic, but you do need consistent telemetry that survives a provider or control-plane change.
FeatBit's Track Insights API supports feature flag usage events and custom metric events. The important operating principle is broader than one API: exposure and outcome events should identify the stable route and flag variation, not only the vendor model name that happened to run that day.
Choose The Right Abstraction Boundary
Vendor-agnostic AI feature flags work best when the boundary is narrow. Abstract the release decision, not the entire AI stack.
Use this decision table:
| Decision | Keep vendor-agnostic | Let it stay implementation-specific |
|---|---|---|
| Rollout eligibility | Yes. It belongs in the flag contract. | No. Hidden eligibility inside the gateway weakens auditability. |
| Route profile name | Yes. Use stable names such as support_balanced_v2. |
Avoid raw model IDs as the only variation meaning. |
| Provider credentials | No. Keep outside flags. | Yes. Store in the service or gateway that owns secrets. |
| Prompt text | Usually no. Store prompt versions in the prompt system or repository. | Yes, unless the flag intentionally selects a reviewed prompt profile. |
| Experiment assignment | Yes. Keep assignment stable and observable. | Avoid ad hoc randomization inside provider-specific code. |
| Provider retry logic | Usually no. It belongs in the gateway. | Yes. This can depend on provider behavior. |
| Rollback path | Yes. It is a release decision. | Do not bury rollback in the model call layer only. |
This keeps the abstraction valuable without pretending every provider feature has an identical equivalent. Some capabilities will remain provider-specific. The job of a vendor-agnostic flag is to keep the product release decision stable while the execution layer adapts.
Migration Runway: From Custom Flags To A Portable Control Plane
You do not have to rewrite every flag at once. Start with AI decisions where lock-in would be expensive:
- Inventory AI runtime decisions: prompts, models, retrieval, guardrails, tools, fallbacks, and experiments.
- Mark which decisions are currently hard-coded to one provider, one gateway, or one flag SDK.
- Rename raw provider variations into route profiles with stable product meaning.
- Add default behavior and fallback route definitions for every AI behavior flag.
- Move provider-specific mapping into the service or gateway that owns execution.
- Standardize exposure and outcome events around flag key, variation, route, and assignment unit.
- Use an OpenFeature-compatible provider or wrapper where SDK portability matters.
- Keep lifecycle metadata so temporary AI flags have owners, review dates, and cleanup rules.
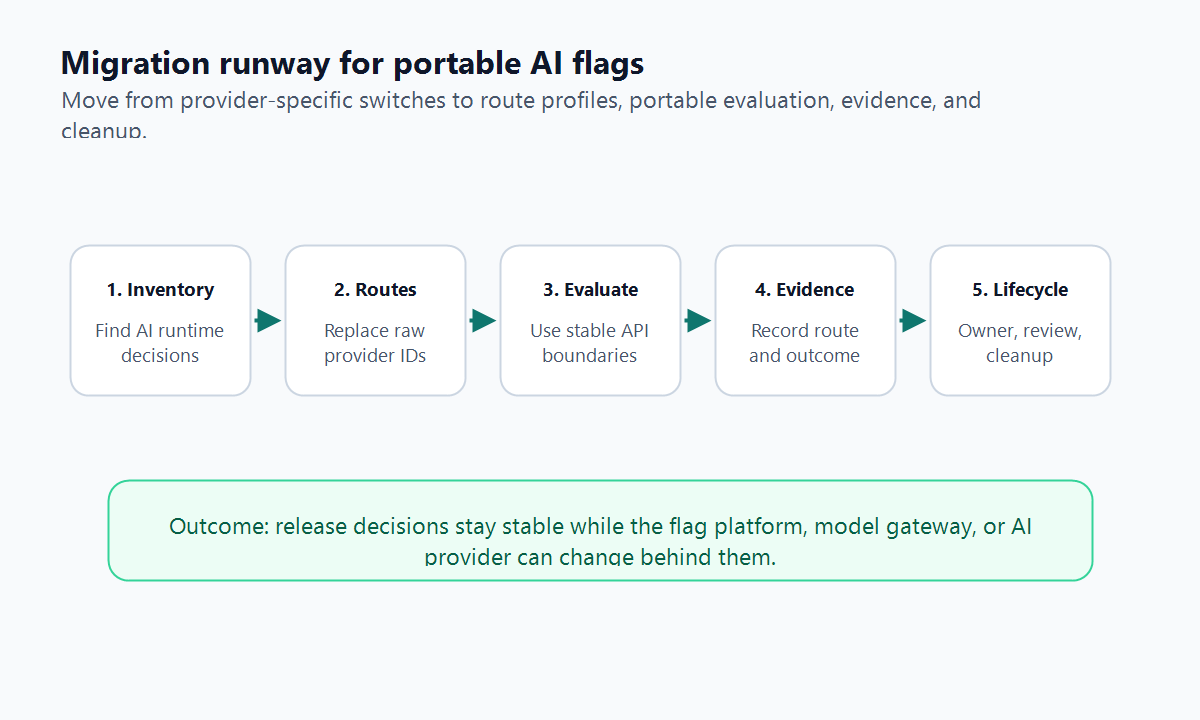
This sequence gives platform teams a practical path. First make the flag value meaningful. Then make evaluation portable. Then make evidence portable. Then make cleanup enforceable.
FeatBit's feature flag lifecycle management guidance is the companion discipline. A portable flag that no one owns still becomes release debt. The contract should include owner, purpose, expected lifetime, rollout evidence, decision state, and cleanup condition.
Where FeatBit Fits
FeatBit's role in a vendor-agnostic AI flag strategy is the release-control layer: typed variations, targeting, progressive rollout, auditability, usage events, experiment metrics, and self-hosted control when teams want ownership of their flag infrastructure.
For teams that want a standard application API, FeatBit maintains OpenFeature providers for several server-side and client-side SDK paths, including Node.js, .NET, Java, and JavaScript providers listed in FeatBit's open-source repositories. For teams that want infrastructure control, FeatBit's self-hosted feature flag platform path lets the control plane run closer to the organization that owns the data, deployment model, and governance requirements.
The practical architecture is:
- use a stable flag contract in application code;
- use FeatBit or an OpenFeature provider behind that contract;
- evaluate AI behavior server-side when the flag controls prompts, models, retrieval, tools, cost, or safety;
- send exposure and outcome events that reference the stable variation and route;
- keep provider-specific execution inside the AI service or gateway.
For rollout mechanics, FeatBit's safe AI deployment page covers internal targeting, canary exposure, metric gates, full release, and rollback. For evaluation placement, the guide on client-side versus server-side AI flag evaluation explains why AI behavior flags should usually be evaluated in a trusted runtime.
Common Pitfalls
A single global ai_enabled flag. It is useful as an emergency switch, but it does not separate prompt, model, retrieval, tool, guardrail, and fallback decisions. You cannot migrate or experiment cleanly if every AI behavior shares one switch.
Raw provider IDs as product variations. A variation named after one model provider is hard to interpret after migration. Use route names that describe the approved behavior, then map route names to provider calls in the execution layer.
Randomization hidden in the model gateway. If the gateway silently splits traffic, product and engineering teams lose the audit trail, targeting rules, and rollback path. Keep experiment assignment visible in the release-control layer.
Telemetry tied only to provider fields. If outcome events only record provider model names, historical evidence becomes harder to compare after a provider change. Record stable route and variation identifiers.
Ignoring lifecycle cleanup. Vendor-agnostic contracts do not remove the need to clean up temporary flags. They make cleanup safer because the flag's purpose and route contract are explicit.
The Short Checklist
Before shipping an AI feature flag that should stay portable, check:
- The flag key names a release decision, not a vendor implementation.
- The value is typed and validated before AI behavior runs.
- The variation uses stable route names instead of raw provider IDs.
- The application has a safe default and fallback route.
- The evaluation context includes the assignment unit and risk context.
- Exposure and outcome events record flag key, variation, route, and execution facts.
- Provider-specific prompt assembly, credentials, retries, and model calls stay in the AI service or gateway.
- The flag has an owner, review date, decision rule, and cleanup condition.
Vendor-agnostic AI feature flags are not an abstraction exercise. They are an operating model for AI release control. Keep the release decision stable, keep execution replaceable, keep evidence portable, and keep rollback available before a provider or platform change turns into a product rewrite.
Source Notes
- OpenFeature: homepage and flag evaluation specification for vendor-agnostic feature flag APIs, typed evaluation, evaluation context, providers, domains, default values, and detailed evaluation metadata.
- OpenTelemetry: semantic conventions for generative AI systems for shared telemetry vocabulary around AI system behavior.
- FeatBit implementation context: AI control layer, safe AI deployment, feature flag lifecycle management, self-hosted feature flags, and the Track Insights API.