Optimizely vs LaunchDarkly for an AI Control Plane: What Buyers Should Compare
If you are comparing Optimizely vs LaunchDarkly for an AI control plane, the useful question is not which vendor has the stronger AI headline. The useful question is which operating model can control one real AI release: select the behavior before it runs, target the first audience, measure the actual outcome, roll back precisely, and leave an audit trail the team can explain later.
LaunchDarkly is the clearer public reference when the buyer wants a dedicated AI runtime configuration surface. Its AgentControl documentation describes configs for prompts, instructions, model settings, variations, targeting rules, monitoring, experimentation, lifecycle management, and production evaluation.
Optimizely is the clearer public reference when the buyer is already evaluating experimentation, feature management, web testing, traffic allocation, targeted delivery, and AI-assisted experimentation workflows across product and marketing teams.
For AI systems, that difference matters. A prompt, model route, retrieval profile, guardrail mode, fallback, or agent tool policy is not only an experiment variation. It is a production release decision. The comparison should therefore start with the control-plane job, not with a generic feature checklist.
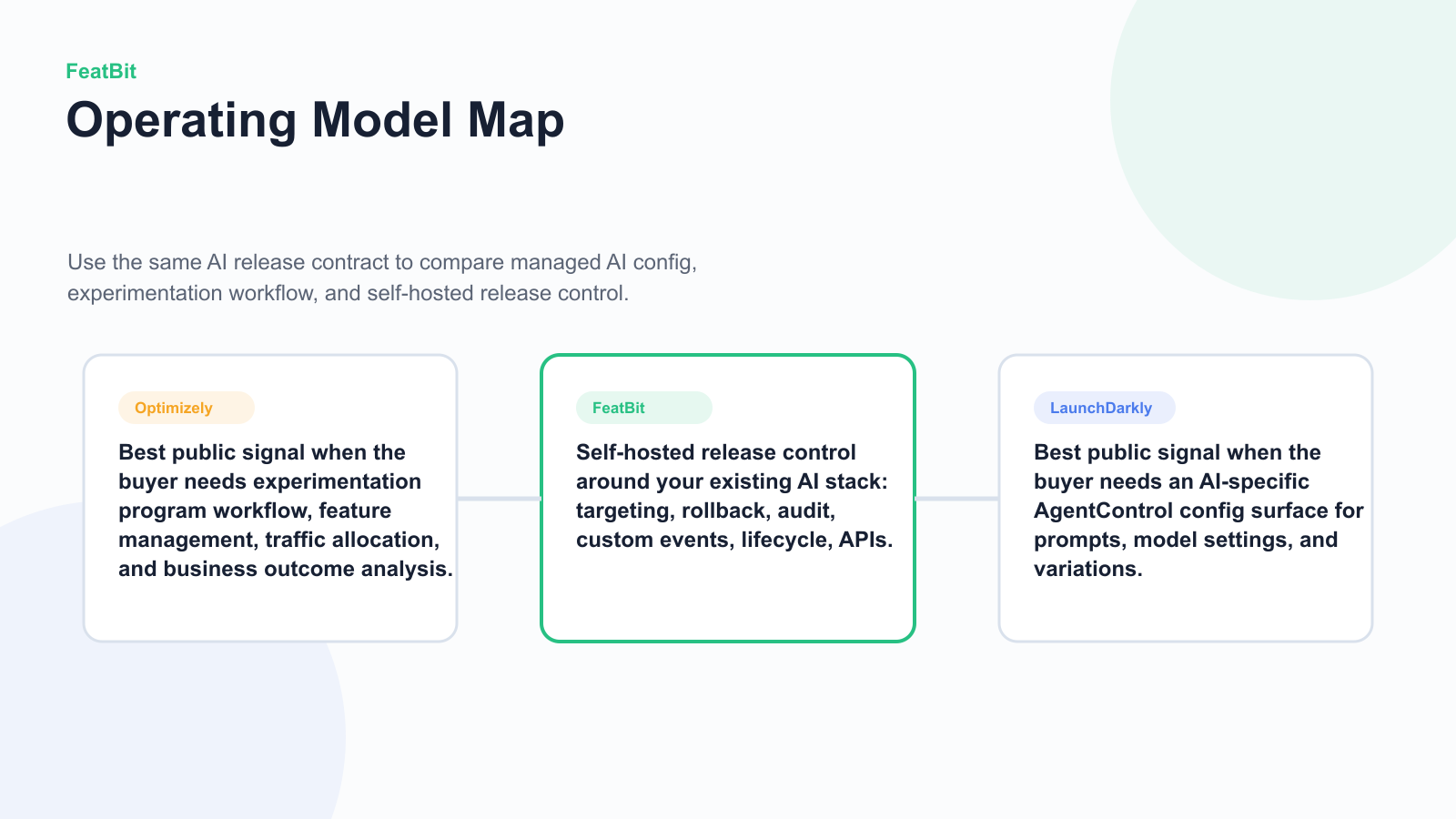
Short Answer
Use this comparison frame:
| Buyer need | LaunchDarkly public fit | Optimizely public fit | FeatBit fit |
|---|---|---|---|
| AI-specific runtime config | Stronger public signal through AgentControl configs, variations, targeting, monitoring, experiments, and lifecycle. | Possible through feature flags and dynamic configuration, but public positioning is broader experimentation and feature management. | Fits when AI execution stays in your app and FeatBit controls release decisions through flags, targeting, rollback, audit, and self-hosting. |
| Experiment program ownership | Supports experimentation and AgentControl experiments, including metrics attached to configs. | Stronger public signal for experimentation programs, feature experimentation, web experimentation, bandits, metrics, and AI-assisted experiment work. | Fits when feature flags, experiments, custom events, rollout, and rollback should live in one release-control loop. |
| Runtime enforcement point | Verify whether the SDK and config evaluation fit the service that chooses prompts, models, retrieval, or tools. | Verify whether Feature Experimentation SDK decisions sit where the AI behavior actually runs. | Evaluate server-side before AI execution, then connect variation, outcome events, audit, and cleanup. |
| Deployment and data boundary | Verify current hosting, plan, privacy, data flow, and add-on requirements directly. | Verify current hosting, SDK, data, and experimentation-plan requirements directly. | Core angle: open-source and self-hosted feature flags, experimentation, audit, APIs, automation, and lifecycle management. |
This is not a ranking. It is a buyer map. LaunchDarkly and Optimizely both have public surfaces that matter for AI-era release work, but they emphasize different operating models. FeatBit enters the decision when the team wants a self-hosted release-control layer around an AI stack it already owns.
Define The AI Control-Plane Job First
"AI control plane" is too broad unless the buyer makes it operational. For a feature flag or experimentation platform, the control plane should answer these questions:
- Which approved AI behavior should run for this user, account, tenant, workflow, region, or rollout stage?
- Where is the decision evaluated before the prompt, model route, retrieval profile, tool mode, or fallback executes?
- Which variation actually served the request, including fallback state?
- Which metric decides expansion, pause, rollback, or cleanup?
- Who changed the control state, which audience changed, and why?
- Can the team reverse one behavior or segment without redeploying the application?
Those questions make the vendor comparison concrete. A page-level experiment, a model-route experiment, an agent workflow, and a prompt rollout all need different evidence. The platform fit depends on which release decision you are trying to control.
FeatBit's AI control layer and safe AI deployment pages use this same operating model: every AI behavior change should be targetable, measurable, reversible, and cleanable after the decision.
LaunchDarkly: Dedicated AI Runtime Configuration Signal
LaunchDarkly's public AgentControl documentation says AgentControl is used to customize, test, and roll out new LLMs in generative AI applications. It describes an AgentControl config as a resource for controlling how an application uses LLMs, including prompts, instructions, model settings, variations, targeting rules, monitoring, experimentation, and lifecycle management.
The same documentation distinguishes completion mode from agent mode. Completion mode configures prompts using messages and roles for single-step model responses. Agent mode configures structured, multi-step workflows using instructions. LaunchDarkly also notes that tool usage depends on how the application and SDK are implemented, not only on the selected configuration mode.
That gives buyers a clear interpretation: LaunchDarkly should be evaluated first when the search phrase "AI control plane" really means "a managed AI config workflow inside the feature management platform."
Ask LaunchDarkly to prove the path with one real AI behavior:
- a baseline prompt, model, retrieval, guardrail, or tool profile;
- a candidate profile with a safe fallback;
- server-side or trusted-runtime evaluation before AI execution;
- targeting for internal users, beta accounts, a tenant segment, or a small percentage;
- monitoring for AI metrics such as latency, token use, or call duration where relevant;
- experimentation for end-user outcomes when the release decision needs product evidence;
- rollback and lifecycle cleanup after the decision.
LaunchDarkly's AgentControl experimentation documentation also separates monitoring from experimentation. Monitoring can show config performance signals, while experimentation measures how config variations affect end-user behavior through defined metrics. That distinction is useful for AI releases because a lower-cost model route is not automatically the better product outcome.
Optimizely: Experimentation And Feature Management Signal
Optimizely's public Feature Experimentation documentation describes a platform for feature flags and experimentation across websites, mobile apps, chatbots, APIs, smart devices, and other connected applications. It says teams can deploy code behind feature flags, experiment with A/B tests, and use targeted deliveries to roll out or roll back flags.
Optimizely's Feature Management product page emphasizes targeted delivery, gradual rollout, instant kill switches, dynamic configuration, flag governance, lifecycle, SDK support across backend, mobile, and edge, and a remote MCP server for experiments and feature flags. Its experimentation page positions "agentic experimentation" around AI-assisted testing, server-side control, web testing, multivariate tests, bandits, and business outcome analysis.
That gives buyers a different interpretation: Optimizely should be evaluated first when the AI control-plane question is tied to a broader experimentation operating model, especially when product, growth, web, content, and engineering teams already coordinate through experimentation workflows.
Ask Optimizely to prove the path with one real AI behavior:
- whether the AI change is a web experience, backend feature, model route, recommendation strategy, or agent workflow;
- where the Feature Experimentation decision is evaluated;
- whether the assignment unit is user, account, conversation, request, or workflow;
- how actual exposure records prompt, model, retrieval, fallback, latency, cost, and quality facts;
- which custom events and metrics decide expansion or rollback;
- how an operator pauses, rolls back, or shuts off one risky variation;
- how flags and experiment artifacts are archived or cleaned after the decision.
Optimizely's experimentation distribution documentation describes Stats Accelerator, multi-armed bandits, and contextual bandits as traffic-allocation approaches for different experiment intents. Those methods may be useful, but they do not replace the runtime proof: the application still has to select the right AI behavior, record what actually ran, and keep rollback available.
The Proof Of Concept Both Vendors Should Pass
Do not compare Optimizely and LaunchDarkly with a demo toggle. Use one AI behavior and make each option implement the same release-control contract.

ai_release_contract:
behavior: support_answer_profile
baseline: support_baseline_v3
candidate: citation_first_v4
controlled_surfaces:
- prompt_profile
- model_route
- retrieval_profile
- fallback_behavior
assignment_unit: account
first_audience: internal_support_users
rollout_path:
- internal
- 5_percent_beta_accounts
- 25_percent_eligible_accounts
primary_metric: resolved_without_escalation
guardrails:
- citation_failure_rate
- p95_latency
- fallback_rate
- estimated_cost_per_case
rollback: return_targeted_accounts_to_support_baseline_v3
cleanup: promote_winner_or_remove_candidate_after_decision
Then score the proof of concept against the same criteria.
| Verification area | Pass signal | Failure signal |
|---|---|---|
| Evaluation point | The control is evaluated before prompt assembly, model routing, retrieval, tool selection, or fallback. | The platform records a page view or dashboard assignment but cannot prove what AI behavior ran. |
| Targeting context | The rollout can target the real risk context: tenant, account, region, plan, workflow, environment, risk tier, or cohort. | Targeting only matches a generic user or page context that does not match the AI release. |
| Structured variation | Variations can express a reviewed profile, not only on and off. |
Prompt, model, retrieval, and fallback decisions are scattered across unrelated settings. |
| Actual exposure | Events record assigned variation and actual behavior served, including fallback state. | Candidate traffic that fell back to baseline is still counted as clean candidate exposure. |
| Evidence loop | Primary and guardrail metrics connect to the variation and assignment unit. | The dashboard can split traffic, but outcome evidence lives in another system with no join key. |
| Rollback precision | One behavior or audience can return to baseline without redeployment. | The only safe rollback is turning off the whole AI feature. |
| Audit and lifecycle | The team can reconstruct owner, change history, decision evidence, and cleanup. | Old prompts, model routes, or experiment flags remain indefinitely. |
This is the point where vendor language becomes less important. The better fit is the platform that makes the release decision easiest to explain under production evidence.
Where FeatBit Fits Beside Optimizely And LaunchDarkly
FeatBit should not be described as LaunchDarkly AgentControl or as Optimizely Agentic Experimentation. Its stronger role is release-decision infrastructure: feature flags, targeting, percentage rollout, experimentation, audit, custom events, APIs, automation, lifecycle management, and self-hosted deployment around the AI behavior your application already executes.
For an AI control-plane comparison, FeatBit is worth evaluating when:
- your team already has a prompt registry, model gateway, retrieval service, eval pipeline, or observability stack;
- rollout state, audit history, flag data, or event pipelines should stay in your infrastructure;
- AI and non-AI releases should share the same feature flag governance model;
- platform teams need REST API, CLI, MCP, webhook, OpenFeature, or agent-assisted automation around flag work;
- temporary AI controls need owner, evidence, decision state, and cleanup rules;
- the proof of concept values runtime release control more than a vendor-specific AI configuration UI.
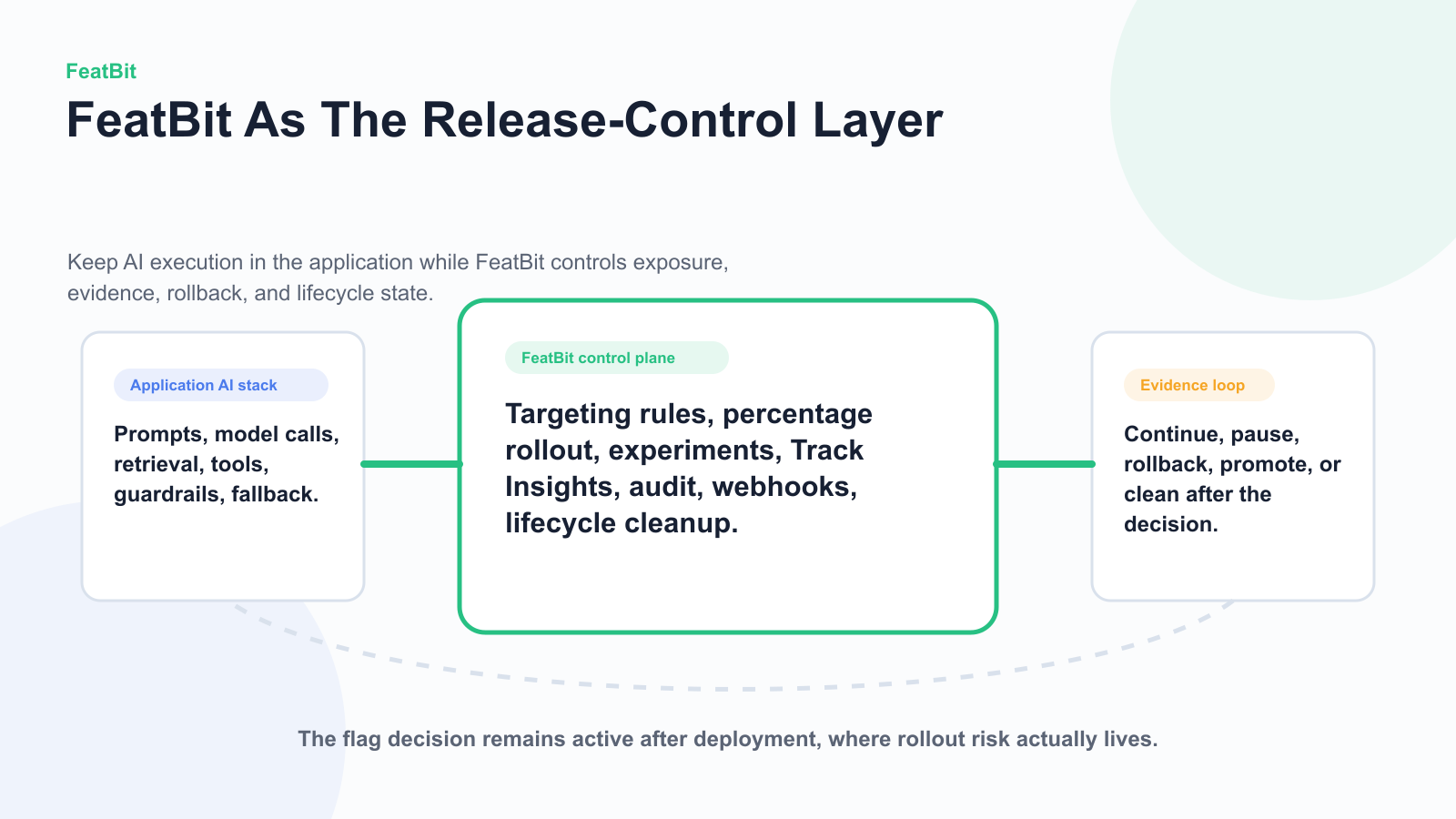
A FeatBit-centered architecture usually looks like this:
- The application, gateway, or agent orchestrator owns prompts, model calls, retrieval, tools, guardrails, and fallbacks.
- FeatBit evaluates the release decision for the current context before that behavior runs.
- The application records exposure and execution facts when the behavior actually serves.
- FeatBit insights, the Track Insights API, experiments, observability integrations, or exported data help decide continue, pause, rollback, or cleanup.
- Operators adjust targeting, rollout, and rollback from the same control plane used for ordinary software releases.
This operating model pairs naturally with FeatBit's self-hosted feature flag platform, AI experimentation, and feature flag lifecycle management guidance.
Common Mistakes In This Comparison
Comparing AI labels instead of request-path control. A product surface can be useful, but the release owner still needs to know exactly where the AI behavior is selected and enforced.
Treating experimentation as rollback. Experiment results can tell the team what happened. The control plane still needs a prepared rollback action.
Using one global AI switch. An emergency kill switch is useful, but day-to-day AI release control usually needs separate decisions for prompt profile, model route, retrieval, tool authority, fallback, experiment exposure, and incident mode.
Skipping actual exposure. Assignment is not the same as served behavior when a model provider times out, a guardrail blocks output, or the application falls back to baseline.
Ignoring data boundaries. AI config metadata, prompts, traces, evaluation records, audit history, and custom events may carry sensitive operational context. Decide where those records should live before committing to a hosted, self-hosted, or hybrid model.
Leaving the control plane dirty. Temporary AI flags, prompts, model routes, and experiment artifacts need owners, decision records, and cleanup expectations.
Bottom Line
Optimizely vs LaunchDarkly for an AI control plane is not a single feature-by-feature contest.
LaunchDarkly has the clearer public signal when the buyer wants a dedicated AI runtime configuration workflow through AgentControl. Optimizely has the clearer public signal when the buyer wants a broad experimentation and feature-management operating model with AI-assisted experimentation, feature rollout, traffic allocation, and business outcome analysis.
FeatBit is the evaluation path when the team wants self-hosted release control around AI behavior: target the first audience, evaluate a typed profile before execution, track actual exposure, connect evidence, roll back precisely, audit the decision, and clean up temporary controls.
The practical next step is simple: choose one real AI release and ask each platform to implement the same release-control contract. The right control plane is the one that keeps the decision targetable, measurable, reversible, auditable, and understandable after production traffic has seen the candidate behavior.
Source Notes
- LaunchDarkly vendor context: LaunchDarkly's AgentControl documentation, reviewed June 24, 2026, is used for public claims about configs, completion mode, agent mode, prompts, instructions, model settings, variations, targeting rules, monitoring, experimentation, lifecycle management, and application-side tool implementation.
- LaunchDarkly experimentation context: LaunchDarkly's AgentControl experimentation documentation, reviewed June 24, 2026, is used for the distinction between config monitoring and experiments that measure end-user behavior with defined metrics.
- Optimizely Feature Experimentation context: Optimizely's Feature Experimentation introduction, reviewed June 24, 2026, is used for public claims about feature flags, A/B tests, targeted delivery, rollback, SDKs, server-side and client-side implementation, remote configuration, and cross-platform experimentation.
- Optimizely product context: Optimizely's Feature Management and Experimentation product pages, reviewed June 24, 2026, are used for public positioning around targeted delivery, gradual rollout, kill switches, dynamic configuration, flag lifecycle, server-side control, AI-assisted experimentation, multivariate tests, and business outcome analysis.
- Optimizely allocation context: Optimizely's experimentation distribution methods, reviewed June 24, 2026, are used for public context on Stats Accelerator, multi-armed bandits, and contextual bandits.
- FeatBit implementation context: AI control layer, safe AI deployment, AI experimentation, self-hosted feature flags, feature flag lifecycle management, targeting rules, percentage rollouts, and the Track Insights API support the release-control workflow described here.
- Related FeatBit reading: LaunchDarkly AI Configs alternative, which feature flag platform supports AI Configs, Optimizely model A/B testing for AI release decisions, and feature flag AI control plane.
- This article compares public documentation signals and operational evaluation criteria. It does not claim private roadmap details, pricing advantage, benchmark results, security rankings, compliance status, customer outcomes, or universal superiority for any vendor.
Image And Open Graph Notes
- Use
/images/blogs/optimizely-vs-launchdarkly-ai-control-plane/cover.pngas the Open Graph image because it frames the page as an Optimizely vs LaunchDarkly AI control-plane buyer guide. - Use
decision-map.pngnear the opening because it separates the LaunchDarkly, Optimizely, and FeatBit operating models. - Use
poc-checklist.pngin the proof-of-concept section because it turns the comparison into a concrete evaluation workflow. - Use
featbit-control-layer.pngnear the FeatBit section because it shows how FeatBit can sit around an application-owned AI stack.