Which Feature Flag Platform Supports AI Observability?
If you mean a named AI observability product surface inside a feature flag and product analytics platform, PostHog is a clear public example. Its documentation has an AI Observability section for capturing traces, generations, and spans from AI and LLM products, and its feature flags documentation describes rollouts, kill switches, targeting, experiments, and remote config.
If you mean the broader capability, the better buyer question is different: can the platform connect a feature flag variation to AI quality, latency, cost, errors, user outcomes, rollback, and audit evidence?
FeatBit supports that release-observability pattern through feature flags, targeting, percentage rollouts, flag insights, the Track Insights API, audit logs, webhooks, and observability integrations such as OpenTelemetry and Datadog. FeatBit should not be described as a native LLM tracing product, model provider proxy, or prompt monitoring vendor. Its strongest role is the release-control layer that labels who received which AI behavior and gives teams a reversible control point while observability and evaluation systems collect evidence.
The Short Answer
Public documentation checked on June 26, 2026 supports this practical answer:
| Question | Practical answer |
|---|---|
| Which feature flag platform publicly documents a named AI observability surface? | PostHog documents AI Observability for AI and LLM products, alongside feature flags in the same broader product platform. |
| Does AI observability support require a named AI observability product? | No. For many teams, the requirement is to join flag exposure with AI traces, metrics, eval results, cost, latency, and business outcomes. |
| Can FeatBit support AI rollout observability? | Yes, when the job is release observability: label AI exposure by flag variation, observe rollout health, send custom metrics, integrate with observability tools, and roll back or narrow exposure. |
| What should a buyer verify? | Whether the platform provides native AI traces, rollout evidence, metric events, experiment analysis, rollback triggers, audit history, data export, and the deployment model your team needs. |
The difference matters because "AI observability" can mean two related but separate jobs. One job is AI telemetry capture: traces, spans, prompts, model calls, token usage, costs, and generations. The other job is rollout observability: which users or accounts received a candidate AI behavior, whether guardrails stayed healthy, and whether operators should expand, pause, or roll back.
A feature flag platform does not have to own both jobs to be useful. But it must make its boundary clear.
What AI Observability Means For Feature Flag Platforms
For feature flag platforms, AI observability should not stop at "we have a dashboard." The platform must help answer a release question:
Should this AI behavior keep expanding to more users?
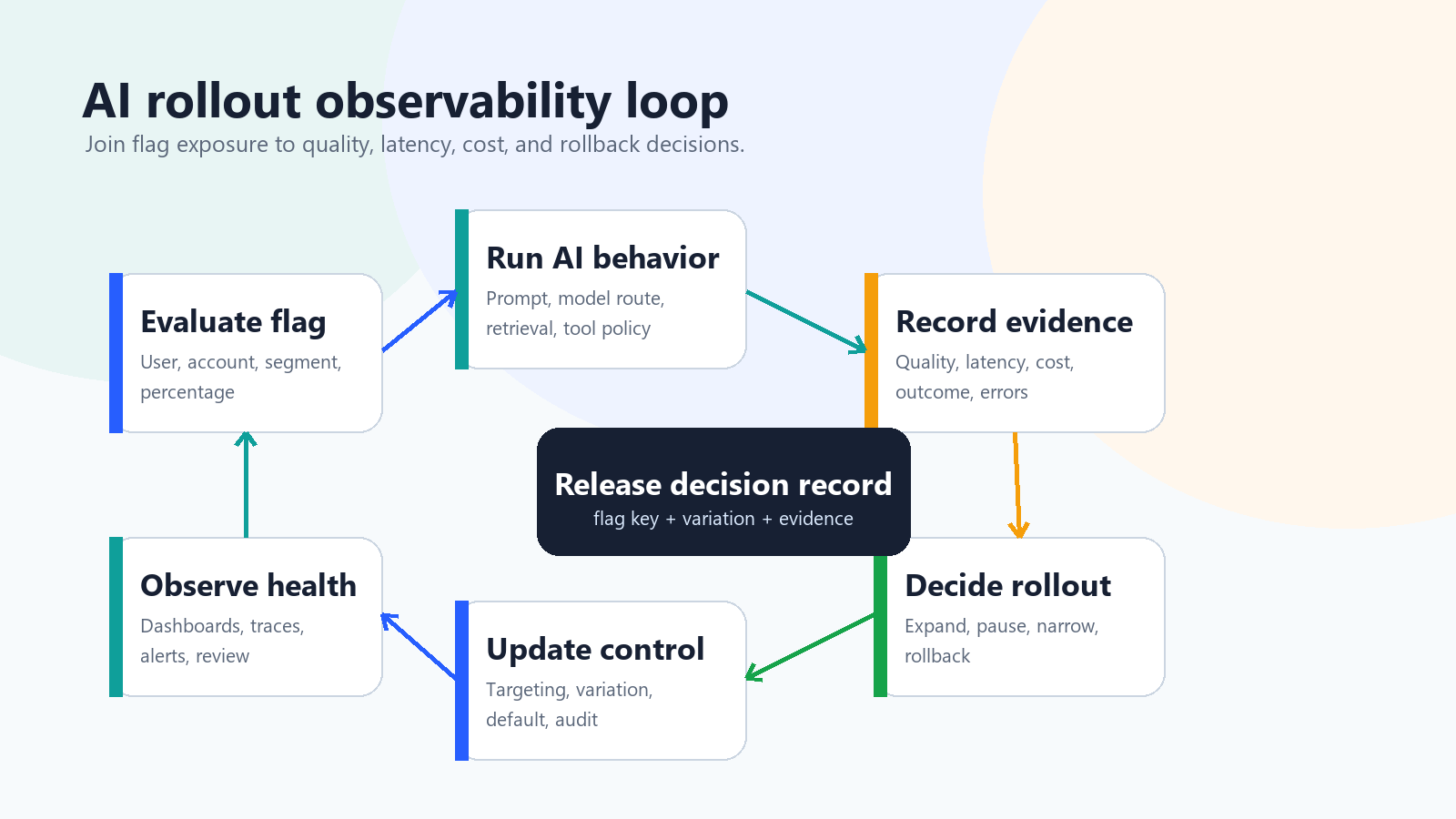
That question requires more than model-call telemetry. A useful release view needs five linked records:
- Exposure: the flag key, variation, assignment unit, environment, segment, and rollout stage.
- Execution: the prompt profile, model route, retrieval setting, guardrail mode, tool policy, or fallback that actually ran.
- Health: latency, provider errors, fallback rate, timeout rate, token usage, cost, and infrastructure signals.
- Quality: human review, evaluator score, correction rate, complaint rate, task success, escalation, or support outcome.
- Decision: expand, pause, narrow, roll back, keep observing, or clean up.
OpenTelemetry's current documentation points readers to a separate GenAI semantic conventions repository, which is a sign that AI telemetry is becoming a specific instrumentation area rather than just ordinary HTTP tracing. That strengthens the need to connect flag exposure with the AI telemetry layer instead of treating rollout control and observability as unrelated systems.
A Buyer Checklist For AI Observability Support
Use this checklist before treating "AI observability" as a procurement checkbox.

| Capability | Buyer question | Why it matters |
|---|---|---|
| Native AI telemetry | Does the platform capture LLM traces, generations, spans, prompts, token usage, and provider metadata itself? | This matters if you want one vendor UI for AI call inspection. |
| Feature flag exposure labels | Can every AI request record the flag key, variation, assignment unit, segment, and rollout stage? | Without exposure labels, quality and cost data cannot support a rollout decision. |
| Custom metric events | Can product outcomes, quality scores, cost, latency, fallback, and correction events be sent back to the platform or joined elsewhere? | AI health is multi-dimensional; uptime alone is not enough. |
| Observability integrations | Can flag evaluations and flag changes appear in tools such as OpenTelemetry, Datadog, New Relic, Grafana, or your warehouse? | Many AI teams already operate traces and dashboards outside the flag system. |
| Rollback or trigger path | Can alerts, metric thresholds, or operator actions reduce exposure or restore a safer variation? | Observability without a control path leaves teams watching a problem spread. |
| Audit and governance | Can the team reconstruct who changed the AI rollout, when, why, and for which environment? | AI rollout decisions often affect cost, customer trust, support load, and policy risk. |
| Deployment model | Can the control plane and telemetry records run where your data and compliance posture require? | Hosted AI observability may not fit every prompt, trace, tenant, or regulated workflow. |
This is why the answer is rarely a single vendor name. A platform with native AI observability may reduce integration work. A platform with strong feature flag, experiment, and integration primitives may be the better release-control layer when AI telemetry already lives in an observability stack.
Where PostHog Fits
PostHog is relevant to this question because its public documentation contains both a feature flag product area and an AI Observability area. The AI Observability docs describe capturing AI and LLM traces, generations, and spans, while the feature flag docs describe toggling features for cohorts or individuals, phased rollouts, kill switches, targeting, A/B testing, and remote config.
That makes PostHog a reasonable answer when the reader is asking, "Which platform publicly offers AI observability and feature flags in the same product ecosystem?"
The caveat is that documentation presence is not the same as architectural fit. A buyer still has to verify SDK coverage, data retention, prompt redaction, model provider support, pricing, data residency, experiment requirements, and whether rollout decisions can be tied to the signals that matter for their AI product.
Where FeatBit Fits
FeatBit's answer is release observability, not native LLM tracing.
Use FeatBit when the core problem is:
- controlling which users, accounts, or workflows receive a candidate AI behavior;
- keeping rollout reversible with targeting, percentage rollout, and fallback variations;
- joining flag variation data to quality, latency, cost, error, and product outcome signals;
- sending custom metric events through the Track Insights API;
- observing flag evaluation volume through flag insights;
- connecting FeatBit services to observability backends through OpenTelemetry;
- using Datadog integration, New Relic, Grafana, webhooks, or triggers around flag changes and performance signals;
- preserving release governance with audit history and lifecycle cleanup.
This matches FeatBit's broader AI control layer view: a prompt, model route, retrieval profile, guardrail mode, or tool policy is a production behavior that should be targetable, measurable, auditable, and reversible.
It also keeps responsibility clear. FeatBit can decide and label which AI behavior runs. Your application, model gateway, eval service, observability backend, or warehouse may still own prompt tracing, model call spans, evaluator output, cost accounting, and deep AI debugging.
A Practical Architecture Pattern
For an AI support assistant, the runtime path can look like this:
request
-> build evaluation context
-> evaluate AI behavior flag
-> run selected prompt, model route, retrieval profile, or tool policy
-> record exposure with the selected variation
-> emit traces, cost, latency, fallback, quality, and outcome events
-> review rollout health
-> expand, pause, narrow, roll back, or clean up
The feature flag does not replace observability. It gives observability a release dimension.
For example, a trace can tell you that support_answer_v4 took 2.1 seconds and used a higher-cost model. The flag variation tells you which rollout decision caused that behavior, which segment received it, and which variation should be reduced if quality or cost crosses the threshold.
A minimal event shape might look like this:
{
"userKey": "acct_123:user_456",
"flagKey": "support_ai_answer_profile",
"variation": "citation_first_v4",
"assignmentUnit": "account",
"rolloutStage": "canary_5_percent",
"traceId": "9c1e82a6f3",
"metrics": {
"latencyMs": 2100,
"estimatedCostUsd": 0.018,
"fallbackUsed": false,
"qualityReview": "accepted",
"resolvedWithoutEscalation": true
}
}
The exact schema will vary by stack. The principle is stable: record the served variation close enough to the AI call that downstream telemetry can explain the release decision.
For a broader rollout sequence, pair this architecture with a staged plan such as AI safe deployment, canary releases for LLM features, or an online eval flag.
What Metrics Should Be Visible
AI rollout observability should include at least four metric groups.
| Metric group | Examples | Release decision it supports |
|---|---|---|
| Reliability | provider error rate, timeout rate, fallback rate, retry rate | Is the candidate stable enough to keep running? |
| Latency | p50, p95, p99, queue time, tool wait time | Is user experience still within the service budget? |
| Cost | token usage, cost per request, cost per successful task, tool-call cost | Is the candidate economically viable at the next rollout stage? |
| Quality | evaluator result, human review, correction rate, escalation, complaint, task completion | Is the candidate better enough to justify expansion? |
For AI systems, a single "good" metric is rarely enough. A cheaper model can reduce cost and hurt quality. A higher-quality prompt can increase latency. A broader retrieval profile can improve answers and introduce new data-boundary questions. The platform should help the team see those tradeoffs by variation, segment, and rollout stage.
Vendor Questions To Ask
Ask these questions before selecting a feature flag platform for AI observability:
- Can the platform show native AI traces, or does it only send flag context to another observability tool?
- Can the application attach flag key, variation, and assignment unit to every AI call?
- Can custom metrics include quality, latency, cost, fallback, correction, and task outcome?
- Can dashboards compare AI behavior by variation, segment, account, environment, and rollout stage?
- Can alerts or metric thresholds trigger a rollback, narrower targeting rule, or incident mode?
- Can audit history explain who changed the rollout and when?
- Can temporary AI rollout flags be cleaned up after the decision?
- Can sensitive prompts, traces, tenant IDs, and operational data stay inside the deployment boundary your team requires?
These questions prevent a common mismatch: buying an observability screen when the real problem is controlled exposure, or buying a flag system when the real problem is deep model-call tracing.
Common Mistakes
Treating AI observability as uptime monitoring. AI can be technically available while answer quality, latency, tool use, or cost becomes unacceptable.
Recording intended assignment instead of actual execution. If the application falls back, retries, switches providers, or bypasses a route, the telemetry must show what actually ran.
Ignoring the assignment unit. User-level assignment, account-level assignment, conversation-level assignment, and request-level assignment answer different questions. Choose the unit before exposure begins.
Using observability without a rollback path. A dashboard should lead to an action: expand, pause, narrow, roll back, investigate, or clean up.
Claiming feature parity from category language. A platform may support AI observability as a native product, as a release-control integration pattern, or both. Those are different claims.
Forgetting lifecycle cleanup. AI observability flags can become stale after a model route, prompt, or guardrail becomes default. Treat them as release assets with owners and cleanup criteria.
Bottom Line
If the question is "Which feature flag platform publicly documents AI Observability as a product area?", PostHog is a clear answer based on its current docs.
If the question is "Which feature flag platform can support AI rollout observability?", evaluate the broader capability: exposure labels, variation-level metric events, observability integrations, rollback triggers, audit history, lifecycle management, and deployment control.
FeatBit supports the second pattern as an open-source and self-hostable release-control layer for AI behavior. Use it to control who receives a prompt, model route, retrieval profile, guardrail mode, or tool policy; connect that exposure to evidence; and make the release decision reversible while your observability stack inspects the AI system in depth.
Source Notes
- PostHog category context: AI Observability documents AI and LLM traces, generations, and spans; feature flags documents rollouts, kill switches, targeting, experiments, and remote config.
- FeatBit implementation context: flag insights, Track Insights API, OpenTelemetry integration, Datadog integration, targeting rules, and percentage rollouts.
- Vendor-neutral observability context: OpenTelemetry's Generative AI semantic conventions page now points readers to a dedicated GenAI conventions repository, which supports treating AI telemetry as its own instrumentation concern.
- Related FeatBit reading: which feature flag platform supports AI Configs, A/B for models, online eval flags, AI safe deployment, and self-hosted feature flags.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it visually connects feature flag control with AI service metrics and rollback signals. - Use
ai-observability-loop.pngnear the opening to show the release-observability loop from flag evaluation to rollout decisions. - Use
evaluation-checklist.pngin the buyer checklist section because it summarizes what teams should verify before trusting a platform claim.